Aren’t I supposed to be wishing Happy New Year there? Not this month! One of my readers asked me a question about SQLCODEs and it opened up a quite fascinating can of worms!
What is the SQLCODE?
Anyone reading this blog should already know exactly what the SQLCODE is, however, for those of you out there using Google in 2045, the definition is, at least in COBOL:
The third field within the SQLCA is the SQLCODE, which is a four-byte signed integer and it is filled after every SQL call that a program/transaction makes.
All Clear So Far?
So far so good! In the documentation from IBM is this paragraph about how to handle and process SQLCODEs:
SQLCODE
Db2 returns the following codes in SQLCODE:
• If SQLCODE = 0, execution was successful.
• If SQLCODE > 0, execution was successful with a warning.
• If SQLCODE < 0, execution was not successful.
SQLCODE 100 indicates that no data was found.
The meaning of SQLCODEs, other than 0 and 100, varies with the particular product implementing SQL.
Db2 Application Programming and SQL Guide
So, every programmer I have ever talked to checks if the SQLCODE is 0 – Green! Everything is fine, if the SQLCODE is negative – Bad message and ROLLBACK, if the SQLCODE is +100 – End of cursor or not found by direct select/update/delete – normally 100% Ok, everything else issues a warning and is naturally very dependent on the application and business logic!
What’s Wrong With This Picture?
Well, sometimes zero is not really zero… I kid you not, dear readers! The sharp-eyed amongst you, will have noticed the last bytes of the SQLCA contain the SQLSTATE as five characters. Going back to the documentation:
An advantage to using the SQLCODE field is that it can provide more specific information than the SQLSTATE. Many of the SQLCODEs have associated tokens in the SQLCA that indicate, for example, which object incurred an SQL error. However, an SQL standard application uses only SQLSTATE.
So, it still seems fine, but then it turns out that SQLCODE 0 can have non-all zero SQLSTATEs!
New in the Documentation
At least for a few people this is a bit of a shock. From the SQLCODE 000 documentation:
SQLSTATE
00000 for unqualified successful execution.
01003, 01004, 01503, 01504, 01505, 01506, 01507, 01517, or 01524 for successful execution with warning.
Say What?
Yep, this is simply stating that you have got an SQLCODE 0 but up to nine different SQLSTATEs are possible… This is not good! Most error handling is pretty bad, but now having to theoretically add SQLSTATE into the mix makes it even worse!
What are the Bad Guys Then?
01003 Null values were eliminated from the argument of an aggregate function.
01004 The value of a string was truncated when assigned to another string data type with a shorter length.
01503 The number of result columns is larger than the number of variables provided.
01504 The UPDATE or DELETE statement does not include a WHERE clause.
01505 The statement was not executed because it is unacceptable in this environment.
01506 An adjustment was made to a DATE or TIMESTAMP value to correct an invalid date resulting from an arithmetic operation.
01507 One or more non-zero digits were eliminated from the fractional part of a number used as the operand of a multiply or divide operation.
01517 A character that could not be converted was replaced with a substitute character.
01524 The result of an aggregate function does not include the null values that were caused by evaluating the arithmetic expression implied by the column of the view.
Not Good!
From this list the 01004, 01503, 01506 and especially 01517 just jump right out and scream at you! Here in Europe, we have a right to have our names or addresses correctly written and, in Germany with all the umlauts, it can get difficult if you then have a 01517 but SQLCODE 0 result!
I hope you don’t find this newsletter too unsettling as, after all, Db2 and SQL normally works fine, but I do think that these SQLSTATEs should really have warranted a positive SQLCODE when they were first created…
What do you all think?
TTFN,
Roy Boxwell
Update:
One of my readers wonders how practicle these „errors“ are. A good point, and so here is a nice and easy recreate for the 01003 problem:
CREATE TABLE ROY1 (KEY1 CHAR(8) NOT NULL,
VALUE1 INTEGER ,
VALUE2 INTEGER )
;
INSERT INTO ROY1 (KEY1) VALUES ('A') ;
INSERT INTO ROY1 (KEY1) VALUES ('AA') ;
INSERT INTO ROY1 (KEY1,VALUE1) VALUES ('B', 1) ;
INSERT INTO ROY1 (KEY1,VALUE1,VALUE2) VALUES ('BB', 1 , 1) ;
INSERT INTO ROY1 (KEY1,VALUE1) VALUES ('C', 2) ;
INSERT INTO ROY1 (KEY1,VALUE1,VALUE2) VALUES ('C', 2 , 2) ;
SELECT * FROM ROY1
;
CREATE VIEW ROYVIEW1 AS
(SELECT AVG(VALUE1) AS AVGVAL1, AVG(VALUE2) AS AVGVAL2
FROM ROY1)
;
SELECT * FROM ROYVIEW1
;
This set of SQL ends up with these outputs:
---------+---------+---------+--------
KEY1 VALUE1 VALUE2
---------+---------+---------+--------
A ----------- -----------
AA ----------- -----------
B 1 -----------
BB 1 1
C 2 -----------
KEY1 VALUE1 VALUE2
---------+---------+---------+--------
C 2 2
DSNE610I NUMBER OF ROWS DISPLAYED IS 6
---------+---------+---------+---------+---------+---------+-----
AVGVAL1 AVGVAL2
---------+---------+---------+---------+---------+---------+-----
1 1
DSNT400I SQLCODE = 000, SUCCESSFUL EXECUTION
DSNT418I SQLSTATE = 01003 SQLSTATE RETURN CODE
DSNT415I SQLERRP = DSN SQL PROCEDURE DETECTING ERROR
DSNT416I SQLERRD = 0 0 0 -1 0 0 SQL DIAGNOSTIC INFORMATION
DSNT416I SQLERRD = X'00000000' X'00000000' X'00000000' X'FFFFFFFF'
X'00000000' X'00000000' SQL DIAGNOSTIC INFORMATION
DSNT417I SQLWARN0-5 = W,,W,,, SQL WARNINGS
DSNT417I SQLWARN6-A = ,,,, SQL WARNINGS
DSNE610I NUMBER OF ROWS DISPLAYED IS 1
Hi all! Welcome to the end-of-year goody that we traditionally hand out to guarantee you have something to celebrate at the end-of-year party!
BPOOL
All Db2 releases since the very beginning of time have used Buffer Pools and when Data Sharing came along in DB2 V4 Group Bufferpools got invented. Since then bufferpools have always been with us and sadly no-one seems to really care about them anymore!
Checked?
When was the last time that you actually checked your local and group bufferpools? Have you really seen any problems? The fantastic thing about Db2 is that you can have 1000’s of problems occurring every second or two but it *still* just keeps on truckin‘ !
Where to Begin?
I always like to begin at the beginning and so review where you are right now by downloading and running the SOFTWARE ENGINEERING BufferPool Health check program! It is an extremely light weight tool that you must simply run *locally* on each and every member and it simply lists out what it finds as being bad, horrible or evil!
Old Advice
Refer to my „old“ blog to see what you could/should be checking and how bad it can really get as well.
Whaddya get?
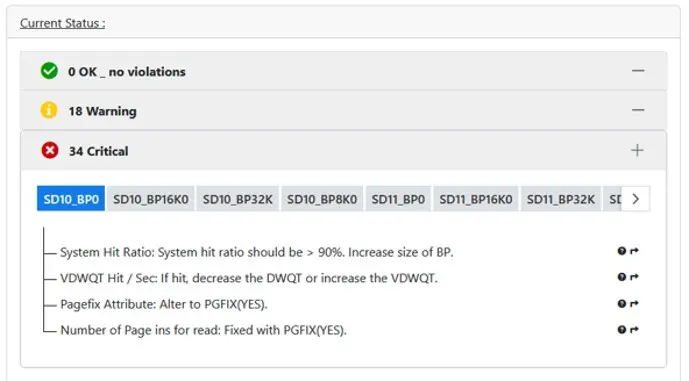
The BufferPool HealthCheck is a one step program that simply lists out whatever it finds as being not good. At the end of the documentation is a table listing out all the checks it does. There is one important check it does *not* do and that is the cross-check between all local bufferpool sizes and the initial size of the related group bufferpool. That is just a little bit too complex for some freeware!
Want more?
If the results help you or you are interested in more, then our SQL WorkLoadExpert for Db2 z/OS product has a new separate licensable Use Case – Buffer Pool which contains all the checks plus the GBP Initial size one.
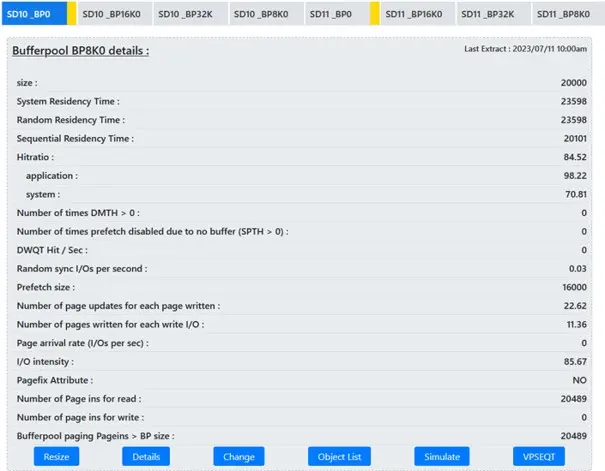
How does it look?
In this screen shot you see the list of Bufferpools being looked at and do you notice the highlights on a couple of tabs? Those yellow stripes should tell you that Bufferpool simulation is on in these two buffferpools. Simulation is really really good, it came in with Db2 11 but most people missed the launch event! Check it out as it is really good but beware! Do not simulate three or more Bufferpools at the same time!
Order By?
The order that you see is the importance list. In my humble opinion this is the list of KPIs that should be worked on from top to bottom and there are more than on this screen grab!
Fixes?
On the right-hand side, we then show you which corrective action is required, if any, to get the bufferpool running better, faster and cheaper!
On the overview highlights we list out what is Good, Bad and Ugly with direct links down to the details. Here will also come a ranking and a highlighting of the Tab to drag your eyes to the problem children that you undoubtedly have!
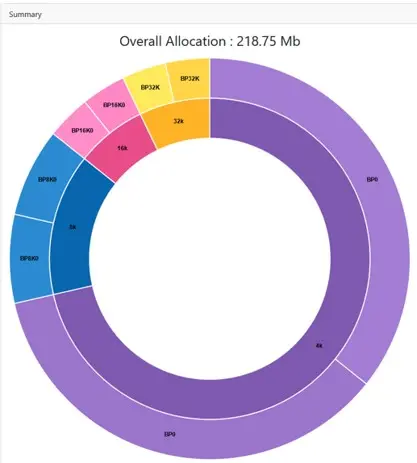
Here finally is then the first „top down“ view of all your local bufferpools so that you can quickly see the sizes and usage of your bufferpools
Naturally it all looks better in RL!
I would dearly love to hear from any of you who run this software and get before and after reviews! I am 100% sure that buffer pools and especially group buffer pools are simply being ignored these days!
This month, I am going to tell you a true story from our labs in Düsseldorf, where I learnt a few things about Db2 and how the Db2 Directory works…
What is it?
The Db2 Directory is the “shadow” catalog if you like. It is basically the machine-readable stuff that echoes what is in some of the Db2 Catalog tables that we all know and love and use nearly every day!
Whatya got?
Well, the Db2 Directory is the DSNDB01 database and, up until Db2 10, was completely hidden from view when looking at it with SQL. The VSAM datasets were there but you could not select from them – Pretty useless! My company, Software Engineering GmbH, actually wrote an assembler program to read the SYSLGRNX table and output the interesting data therein so that it could be used for image copy decisions etc. But, then IBM finally decided to open up the Db2 Directory to our prying eyes! (Sad footnote: They still output the LGRDBID and LGRPSID as CHAR(2) fields!!! Completely useless for joining of course – See my older blogs all about SYSLGRNX and doing the conversion to a correct SMALLINT way of doing it!
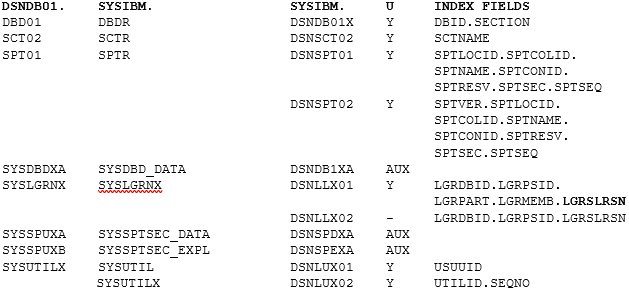
Tables, Tables, Tables
You actually do not have that much data available for use with it!
U is Unique index Y or – for Duplicates allowed and AUX for the standard LOB AUX Index. Bold field names are DESC order.
This table gives you an overview of what you get and also shows the two tablespaces that were, for me at least, of special interest!
Where’s the Beef?
On my test system, the tablespaces SYSSPUXA and SYSSPUXB were both getting larger and larger. Now the task is to understand why you need to know which of the above tables is “linked” to which other ones, and then which link to the Db2 Catalog tables. Time for another table!
So?
What you can see from this, is that the DSNDB01.SPT01 (which we know is the SYSIBM.SPTR) is linked to a whole bunch of Package-related tables and this is all documented – so far, so good! What got me interested, were the LOB tablespaces SYSSPUXA and SYSSPUXB. In my system they were taking up 13,929 and 6,357 Tracks respectively. Might not sound much to a real shop out there, but for me with only 118,000 rows in the SPTR it piqued my interest!
What is in it?
The SYSSPUXA (Table SYSSPTSEC_DATA) contains the machine-readable access paths generated by BIND/REBIND with versioning etc. so that being quite big was, sort of, OK. The SYSSPUXB (Table SYSSPTSEC_EXPL) contains *only* the EXPLAIN-related information for the access path. This was added a few Db2 releases ago so that you could extract the current access path without doing a REBIND EXPLAIN(YES) as that would show the access path “right now” as opposed to what it was, and still is, from, say, five years ago. These two access paths might well be completely different!
How many?
The SPTR had 6,630 tracks.
The SYSSPTSEC_DATA had 13,929 tracks.
The SYSSPTSEC_EXPL had 6,357 tracks.
This is a total of 1,795 Cylinders for 118,553 rows of data – for me, that’s a huge amount.
What is “in” there?
I quickly saw that there were *lots* of versions of packages and some very odd “ghosts” lurking in the data. Here’s a little query to give you a glimpse:
SELECT SUBSTR(SP.SPTCOLID, 1, 18) AS COLLID
, SUBSTR(SP.SPTNAME, 1, 8) AS NAME
, SUBSTR(SP.SPTVER, 1 , 26) AS VERSION
, HEX(SP.SPTRESV) AS RESERVED
FROM SYSIBM.SPTR SP
WHERE 1 = 1
-- AND NOT SP.SPTRESV = X'0000'
AND NOT SP.SPTCOLID LIKE 'DSN%'
AND NOT SP.SPTCOLID LIKE 'SYS%'
LIMIT 100
;
Now, the weird thing is, that the SPTRESV (“RESERVED”) column obviously actually contains the Plan Management number. So, you have “normally” up to three entries. Zero for Original, One for Previous and Two for Current. What I saw, was a large number of Fours!
Set to Stun!
Where did they all come from? A quick bit of looking around revealed that it was Package Phase-In! They have to keep the old and the new executables somewhere… So then, I started trying to work out how to get rid of any old rubbish I had lying around.
FREE This!
First up was a simple FREE generator for old versions of programs deliberating excluding a few of our own packages that require versions for cross-system communications.
WITH NEWEST_PACKAGES (COLLID
,NAME
,CONTOKEN ) AS
(SELECT SP.SPTCOLID
,SP.SPTNAME
,MAX(SP.SPTCONID)
FROM SYSIBM.SPTR SP
WHERE NOT SP.SPTCOLID LIKE 'DSN%'
AND NOT SP.SPTCOLID LIKE 'SYS%'
AND NOT SP.SPTNAME IN ('IQADBACP' , 'IQAXPLN')
GROUP BY SP.SPTCOLID
,SP.SPTNAME
)
SELECT DISTINCT 'FREE PACKAGE(' CONCAT SQ.SPTCOLID
CONCAT '.' CONCAT SQ.SPTNAME
CONCAT '.(' CONCAT SQ.SPTVER
CONCAT '))'
FROM NEWEST_PACKAGES NP
,SYSIBM.SPTR SQ
,SYSIBM.SYSPACKAGE PK
WHERE NP.COLLID = SQ.SPTCOLID
AND NP.NAME = SQ.SPTNAME
AND NP.CONTOKEN > SQ.SPTCONID
AND SQ.SPTCOLID = PK.COLLID
AND SQ.SPTNAME = PK.NAME
AND PK.CONTOKEN > SQ.SPTCONID
AND PK.LASTUSED < CURRENT DATE - 180 DAYS
--LIMIT 100
;
Note that this excludes all IBM packages and my two “SEGUS suspects” and pulls out all duplicates that have also not been executed for 180 days. Running it and then executing the generated FREEs got rid of a fair few, but those “Four” entries were all still there!
FREE What?
Then I found a nice new, well for me anyways, use of the FREE PACKAGE command. You have to be brave, you have to trust the documentation and you trust me because I have run it multiple times now! The syntax must be:
FREE PACKAGE(*.*.(*)) PLANMGMTSCOPE(PHASEOUT)
Do *not* forget that last part!!! Or make sure your resume is up to date!
This then gets rid of all the junk lying around! Was I finished? Of course not… Once it had all been deleted I then had to run a REORG of all these table spaces and so now we come to part two of the BLOG…
REORGing the Directory
Firstly, if you are in Db2 13 you must Reorg the SPT01 and SYSLGRNX anyway to get the new DSSIZE 256GB activated. Secondly, Db2 is clever, so for certain table spaces, it will actually check the LOG to make sure you have taken a COPY:
“Before you run REORG on a catalog or directory table space, you must take an image copy. For the DSNDB06.SYSTSCPY catalog table space and the DSNDB01.DBD01 and DSNDB01.SYSDBDXA directory table spaces, REORG scans logs to verify that an image copy is available. If the scan of the logs does not find an image copy, Db2 requests archive logs.”
Db2 for z/OS Utility Guide and Reference „Before running REORG TABLESPACE“
Pretty clear there!
We are good to go as we only have the SPT01 and its LOBs. Here is an example Utility Syntax for doing the deed:
Pretty simple as the AUX YES takes care of the LOBs. Remember to COPY all objects afterwards as well!
COPY TABLESPACE DSNDB01.SPT01
COPYDDN (SYSC1001)
FULL YES
SHRLEVEL REFERENCE
COPY TABLESPACE DSNDB01.SYSSPUXA
COPYDDN (SYSC1001)
FULL YES
SHRLEVEL REFERENCE
COPY TABLESPACE DSNDB01.SYSSPUXB
COPYDDN (SYSC1001)
FULL YES
SHRLEVEL REFERENCE
How many after?
Once these were all done, I looked back at the track usage:
The SPTR had 4,485 tracks (was 6,630)
The SYSSPTSEC_DATA had 7,575 tracks (was 13,929)
The SYSSPTSEC_EXPL had 4,635 tracks (was 6,357)
This is a total of 1,113 Cylinders (was 1,795) for 90,858 (was 118,553) rows of data.
This is very nice saving of 25% which was worth it for me!
Directory Tips & Tricks
Finally, a mix-n-match of all things Directory and Catalog.
Remember to always reorg the Directory and the Catalog table spaces in tandem.
Remember to always do a COPY before you do any reorgs!
FASTSWITCH YES is ignored for both Catalog and Directory reorgs.
Any more Limits?
Yep, you cannot REORG the DSNDB01.SYSUTILX at all. Only hope here is IDCAMS Delete and Define – dangerous!
LOG YES is required if SHRLEVEL NONE is specified for the catalog LOB table spaces.
If SHRLEVEL REFERENCE is specified, LOG NO must be specified.
The SORTDEVT and SORTNUM options are ignored for the following catalog and directory table spaces:
The COPYDDN and RECOVERYDDN options are valid for the preceding catalog and directory tables if SHRLEVEL REFERENCE is also specified.
Inline statistics with REORG TABLESPACE are not allowed on the following table spaces:
IBM now pack a complete Catalog and Directory REORG with the product to make it nice and easy to schedule and run! Look at member <your.db2.hlq>.SDSNSAMP(DSNTIJCV) for details.
To REORG or not to REORG?
This is the eternal question! For Db2 13 you must do at least two table space REORGs, as previously mentioned, but the hard and fast rule about the complete Db2 Catalog and Directory is: about once per year is normally sufficient. If you notice BIND/PREPARE times starting to go horribly wrong then a REORG is probably worth it, and it may be time to check the amount of COLGROUP statistics you have!
The recommendation from IBM is, “before a Catalog Migration or once every couple of years, and do more REORG INDEX than REORG TS.”
I am now keeping an eagle eye on my Db2 Directory LOBs!
If you have any Directory/Catalog Hints & Tips I would love to hear from you.
Hi! Continuing on with my AI blog (last one. I promise!) I wish to delve into the innards of the USS part of the SQL Data Insights experience and show you what it all costs!
A Quick Review Perhaps?
Please check my older newsletters for everything about install etc. of SQL DI, and one important thing which is the latest Vector Prefetch APARs (also see my last newsletter for details). Now. I will be doing „before and after“ performance reviews with this feature on and off.
Bad News First!
What I have found, is that when I take a 500,000 row table into SQL DI and choose 17 columns, it takes the *entire* machine as well as all local page datasets and I was forced to cancel it after five hours…
Looking in the Logs…
If you go trawling around your Unix Directories, you will trip over these paths:
/u/work/sqldi
Home is Where the Spark is!
This is “home” where all of the SQL DI stuff is “installed”, naturally your name might be different!
Under here is the next layer of interest to me for the Spark processing.
It is Magic!
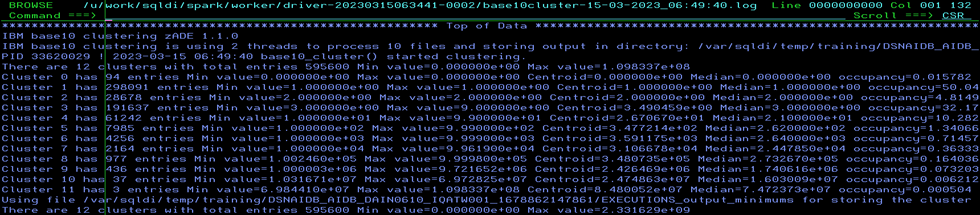
/u/work/sqldi/spark – Now this is where Spark does “the magic” and actually computes all your vector table data. It runs in stages and the first is the Base10 (I guess numeric analysis) part. For my test data it looks like this:
Scroll down to the bottom:
So, this ran really quickly!
Internals…
Then it does a ton of internal stuff and it starts actually doing the learning, which is “progressed” in a file like this:
Just Sitting There, Typing REF and Pressing ENTER…
Of course your name will be different, but just sitting there in OMVS and using the REF command you will see this file grow in size every now and again. When it does, quickly Browse on in and you will see stuff like this:
ibm-data2Vec (1.1.0 for zOS) starting execution using file /var/sqldi/temp/training/DSNAIDB_AIDB_DAI
ibm-data2vec found the required library: libzaio.so. Proceeding with the training..
ibm-data2vec will use following mode: CBLAS
User has not provided training chunk size. Using 1 GB chunk size for reading training file.
ibm-data2Vec is preallocating space for the model using user-provided value 1230314
ibm-data2Vec starting execution using file /var/sqldi/temp/training/DSNAIDB_AIDB_DAIN0610_IQATW001_1
83951683 ! 2023-03-15 07:17:27 ! Time elapsed learning vocab from train file = 145.91525s
Processed 13103200 words in the training file. There are 1213852 unique words in the vocabulary: Pri
Model training code will generate vectors for row-identifier (pk_id) or user-specified primary keys
83951683 ! 2023-03-15 07:17:27 ! Stage 1 completed. Time elapsed during file reading = 145.91643s
Training the database embedding (db2Vec) model using 12 CPU thread(s)
Whole Machine Gone – Oh Oh!
Now, in my case, it just sat there for a while taking all paging, all frames, all ziip and cp cpu and then it wrote out:
Epoch 0 learning rate Alpha=0.024704 Training Progress=5.00%
Epoch 0 learning rate Alpha=0.024404 Training Progress=10.00%
Epoch 0 learning rate Alpha=0.024099 Training Progress=15.00%
Epoch 0 learning rate Alpha=0.023791 Training Progress=20.00%
Epoch 0 learning rate Alpha=0.023486 Training Progress=25.00%
Epoch 0 learning rate Alpha=0.023182 Training Progress=30.00%
Epoch 0 learning rate Alpha=0.022885 Training Progress=35.00%
Epoch 0 learning rate Alpha=0.022582 Training Progress=40.00%
Epoch 0 learning rate Alpha=0.022286 Training Progress=45.00%
Epoch 0 learning rate Alpha=0.021980 Training Progress=50.00%
Epoch 0 learning rate Alpha=0.021673 Training Progress=55.00%
That last line was written out at 12:42 and after starting at 07:17 you can see that I still had nearly a five hour wait ahead of me. Time to cancel and rethink this!
Restart!
Thankfully, on the GUI interface (where you cannot see this progress info, sadly!) the “Stop training” button worked after a while. If it does not respond then you can just issue the
S SQLDAPPS,OPTION='SQLDSTOP'
command to stop it. Then, once all stopped, and the cpus have cooled down a bit, you can select a smaller data set and retry learning!
Smaller is Sometimes Better!
And with 40.000 rows it is much faster:
50397300 ! 2023-03-15 12:17:16 ! Stage 1 completed. Time elapsed during file reading = 26.992490s
Training the database embedding (db2Vec) model using 12 CPU thread(s)
Epoch 0 learning rate Alpha=0.024765 Training Progress=5.00%
Epoch 0 learning rate Alpha=0.024539 Training Progress=10.00%
Epoch 0 learning rate Alpha=0.024308 Training Progress=15.00%
Epoch 0 learning rate Alpha=0.024073 Training Progress=20.00%
Epoch 0 learning rate Alpha=0.023826 Training Progress=25.00%
Epoch 0 learning rate Alpha=0.023591 Training Progress=30.00%
Epoch 0 learning rate Alpha=0.023354 Training Progress=35.00%
Epoch 0 learning rate Alpha=0.023115 Training Progress=40.00%
Epoch 0 learning rate Alpha=0.022878 Training Progress=45.00%
Epoch 0 learning rate Alpha=0.022637 Training Progress=50.00%
Epoch 0 learning rate Alpha=0.022406 Training Progress=55.00%
Naturally, this is heavily dependent on the machine you have, the memory you have and the size of your local paging dataset.
EXPLAIN Yourself!
So now to do some EXPLAIN runs and then a quick comparison of the “double” AI Whammy that I have, quickly followed by the “New” PTF that, hopefully, sorts it all out.
Double Trouble?
You might have noticed that in my test SQLs I have to use the BiF AI twice. Once for the SELECT and once for the WHERE. This is because the use of the AI_VALUE column is not supported in the WHERE predicate.
Naturally, you can re-write the query to look like this:
SELECT * FROM
(SELECT AI_SEMANTIC_CLUSTER( PROGRAM,
'DSNTIAUL',
'DSN§EP2L',
'DSN§EP4L') AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PRIM_AUTHOR , 1 , 8) AS PRIM_AUTHOR
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,SUBSTR(A.REF_TABLE , 1 , 18) AS REF_TABLE
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM DAIN0610.IQATW001 A
WHERE 1 = 1
AND A.PROGRAM NOT IN ('DSNTIAUL',
'DSN§EP2L',
'DSN§EP4L')
AND A.STMT_ORIGIN = 'D'
)
WHERE AI_VALUE IS NOT NULL
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY ;
Does My Work File Look Big to You?
The problem is that now you have a HUGE work file… In my tests it was always much quicker to code the AI BiF twice. After all, it is always „Your Mileage May Vary“, „The Cheque is in the post“ or „It depends“, isn’t it?
AI Does Use the Optimizer!
EXPLAIN Output… The AI Does indeed get output by EXPLAIN (I was surprised about this to be honest!) for the following query:
SELECT AI_SEMANTIC_CLUSTER( PROGRAM,
'DSNTIAUL',
'DSN§EP2L',
'DSN§EP4L') AS AI_VALUE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,SUBSTR(A.PRIM_AUTHOR , 1 , 8) AS PRIM_AUTHOR
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,SUBSTR(A.REF_TABLE , 1 , 18) AS REF_TABLE
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM DAIN0610.IQATW001 A
WHERE 1 = 1
AND A.PROGRAM NOT IN ('DSNTIAUL',
'DSN§EP2L',
'DSN§EP4L')
AND AI_SEMANTIC_CLUSTER( PROGRAM,
'DSNTIAUL',
'DSN§EP2L',
'DSN§EP4L')
IS NOT NULL
AND A.STMT_ORIGIN = 'D'
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY ;
The EXPLAIN output looks like:
Then it gets an interesting STAGE2 RANGE predicate!
which resolves into:
So here we see what the BiF is doing from the perspective of the Optimizer! If you run the nested table version of the query then this line does *not* appear at all!
Notice here that the RANGE is now a STAGE1!
Optimize This!
So IBM Db2 has incorporated it into the Optimizer which is a good thing. But please remember: your SQL can have local predicates that cut down the size of the work file and so evens out the access times… Basically, you must code both and test to see which of the solutions is better for typical usage (As always really…)
Time, Measure, Repeat
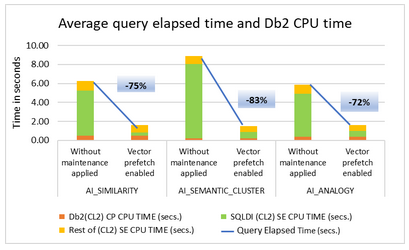
Ok, now just doing one execute of the double query requires 2.58 seconds of CPU and 15.35 seconds elapsed. The statement is *in* the DSC so prepare time can be ignored. Here you can see it has been executed twice so we have average values but I am using the CPU from the batch job as it is more precise.
Changing the query to now fetch back all rows instead of first ten requires 7.06 seconds of CPU and 48.78 seconds elapsed. But it returned over 200K rows!
While the query was running you can see the SQLD SQL DI in SDSF taking quite large chunks of zIIP time…
Now I will enable Vector Prefetch with a value of 10GB to see if it makes an impact for these queries. To do this you must update the ZPARM MXAIDTCACH and then enable the changed ZPARM.
That is Not What I was Expecting!
First query is now 2.56 CPU and 15.26 Elapsed. More like background noise than an improvement. And now with the FETCH FIRST removed 7.07 and 49.36 seconds. I guess my queries are not improved with Vector Prefetch!
Could be Me…
From the IBM Vector Prefetch docu:
With vector prefetch enabled, CPU performance for AI queries with AI function invocation on qualified rows improves particularly when the ratio of the cardinality of qualified rows to the total number of numeric vectors for the column is high.
Now let’s try and see if I can discover something new in real data! Anything sensitive has been obfuscated!
SELECT AI_SIMILARITY( PROGRAM,
'IQADBACP') AS AI_VALUE
,SUBSTR(A.PRIM_AUTHOR , 1 , 8) AS PRIM_AUTHOR
,SUBSTR(A.PROGRAM , 1 , 8) AS PROGRAM
,SUBSTR(A.REF_TABLE , 1 , 18) AS REF_TABLE
,A.WLX_TIMESTAMP
,A.STMT_ID
,A.STMT_TIMESTAMP
,A.EXECUTIONS
,A.GETP_OPERATIONS
,A.ELAPSE_TIME
,A.CPU_TIME
,A.STMT_TEXT
FROM DAIN0610.IQATW001 A
WHERE 1 = 1
AND NOT A.PROGRAM = 'IQADBACP'
AND AI_SIMILARITY ( PROGRAM,
'IQADBACP')
IS NOT NULL
AND A.STMT_ORIGIN = 'D'
ORDER BY 1 DESC -- SHOW BEST FIRST
--ORDER BY 1 -- SHOW WORST FIRST
FETCH FIRST 10 ROWS ONLY;
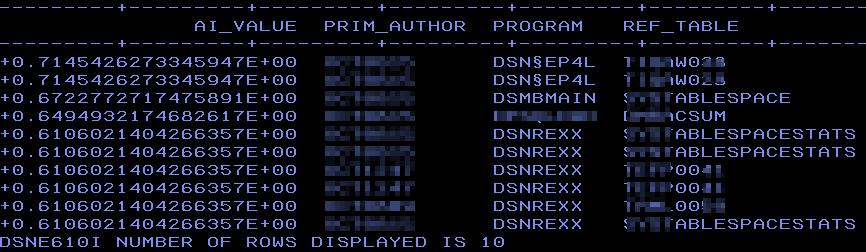
This is similar to my test from last month but now on real data. Note that I have added a predicate A.STMT_ORIGIN = ‚D‘ as I only want Dynamic SQL programs:
Dynamic Hits?
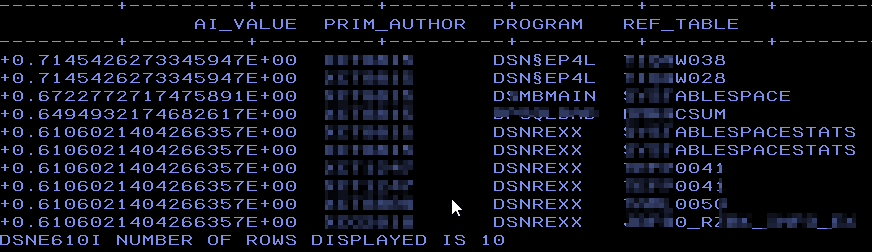
Here you can see that it has found a variety of programs that also do dynamic SQL but I also „helped“ it by only asking for dynamic SQL. So now once again but this time without the predicate A.STMT_ORIGIN = ‚D‘:
Success!
It has found nearly all from the first list but also different ones, crucially it has *not* found any Static SQL!
So, that’s enough of AI for the next few months for me. However, if you have any questions or ideas that I could try out feel free to email!
This year (well, strictly speaking last year…) IDUG EMEA changed from running Monday to Wednesday to being from Sunday to Tuesday. This caught a few people out with travel plans, etc. but all in all it was ok as a „once off“. It was also held after a two-year COVID delay in the beautiful city of Edinburgh, where it normally rains a day longer than your stay but I only had rain on one day! Mind you, that did coincide with tornado style, umbrella-shredding winds that made going anywhere more like a swim, but what can I say? The Haggis was excellent, the Whisky’s were simply gorgeous and all the people were incredibly friendly. Not just the visitors to the IDUG either!
All a bit late, I know, but I have been terribly busy doing other „real“ work… So, with no further ado, off we go through the Db2 for z/OS IDUG presentations!
Please remember, to use the links below you *must* have been at the IDUG 2022 EMEA and/or you are an IDUG Premium member and remember your IDUG Userid and password!
Starting with Track A: Db2 for z/OS I
A01 Db2 13 for z/OS and More! from Haakon Roberts and Steven Brazil gave a great intro to Db2 13, the history behind it and the AI-driving force within. Finishing off with Db2 13 highlights. Our very own Andre Kuerten rated Haakon as the best overall presenter by the way.
A02 Db2 13 for z/OS Performance Overview, from Akiko Hoshikawa did what it said. A deep dive through all the performance stuff, including updates on Db2 12 and synergy with z Hardware.
A03 Db2 13 for z/OS Migration, Function Levels and Continuous Delivery from „The Dynamic Duo“ of Anthony Ciabattoni and John Lyle was a review of all the Db2 12 functions and then an update on how to do the migration to Db2 13 – Which should be faster and less troublesome than to Db2 12.
A04 Now You See It, Unveil New Insights Through SQL Data Insights from Akiko Hoshikawa was the first of many presentations to go into depth all about AI, as various bits of AI are now available out-of-the box with Db2 13. Still a few things to do of course… 50GB of USS data for the SPARK for example … but at least no need for machine learning (ML). At the very end was also a glimpse into the future and the next three BiFs coming our way soon!
A05 Getting Ready for Db2 13 from John Lyle was another review of continuous delivery and how to get to Db2 12 FL510, which is the migration point for Db2 13 FL100.
A06 Db2 for z/OS Utilities – What’s New? from Haakon Roberts was the usual excellent presentation and run down of all the latest new stuff on the utilities front and also any Db2 13 stuff as well. As always well worth a read!
A09 Db2 Z Network Encryption: Overview and How to Identify End-Users Using Open Port from Brian Laube was a fascinating presentation all about fully understanding this problem as it is, or will be, a problem in all shops at some point in the future! The presentation also included an example NETSTAT from TSO to help you find the „bad guys“ before you switch to 100% SECPORT usage. At the end was a very nice list of AHA requests/ideas/wishes which I would also appreciate if some people voted for!
A14 Express Yourself from Marcus Davage was an excellent romp through the horrors of REGEX and ended up with a quick way to solve WORDLE…all a bit dubious if you ask me! What with the recursive SQL from Michael Tiefenbacher and Henrik Loeser solving Sudoku and now Marcus solving Wordle what is left for our brains to do??? The link to github for Sudoku is:
https://github.com/data-henrik/sql-recursion
Thanks to Michael and especially to Henrik for the link.
A15 A Row’s Life from Marcus Davage. This is what a row goes through in its daily life – fascinating! A deep technical dive into the data definition of pages etc etc.
B03 Db2 13 for z/OS Application Management Enhancements from Tammie Dang. The highlights for applications were reviewed, highlighting timeouts and deadlocks and the way that SYSTEM PROFILES can easily help you get what you want without massive REBINDs.
B05 Ready Player One for Db2 13! from Emil Kotrc. This was another recap of Db2 13 migration, CD, Db2 12 FL501 to FL510 but also with deprecated functions and incompatible changes.
B06 Getting RID of RID Pool RIDdles from Adrian Collett and Bart Steegmans was an entertaining sprint through What is an RID? and When do I have a real RID problem?
B10 Db2 for z/OS Data Sharing: Configurations and Common Issues from Mark Rader. Was a very interesting presentation about exactly how data sharing hangs together and the various ways you can break it or make it better. A Must Read if you have, or are planning on, going to a data sharing system! His anecdote about a forklift truck crashing through the back wall of the data center brought home that „disasters“ are just waiting to happen…
B11 Get Cozy with Traces in Db2 for z/OS from Denis Tronin was a great intro into the usage of Traces for Db2 for z/OS. Included was also an update of which traces have been changed or introduced for the new Db2 12 and 13 features.
B12 Partitioning Advances: PBR and PBR RPN from Frank Rhodes. This gave an excellent review of the history of tablespaces in Db2. Then the new variant PBR RPN was introduced, and how to get there.
B13 Managing APPLCOMPAT for DRDA Application from Gareth Copplestone-Jones. Another review of CD and APPLCOMPAT but this time looking at NULLID packages and the special problems they give you!
B14 Afraid of Recovery? Redirect Your Fears! from Alex Lehmann. This showed the new redirected recovery feature with some background info and a summary about why it is so useful!
B16 DB2 z/OS Recovery and Restart from Thomas Baumann. This is a *one* day seminar… The IDUG live talk was just the first hour (first 34 slides!) and if you ever wish to consider doing RECOVER – Read it all!
B17 Security and Compliance with Db2 13 for z/OS from Gayathiri Chandran. Was all about the IBM Compliance Center and a list of all Audit relevant info in Db2 (Encryption, Audit policies etc.)
Now off to Track E AppDev & Analytics I:
E01 When Microseconds Matter from Thomas Baumann. This was all about tuning a highly tuned system. Where, even if you have 50 microsecond CPU SQL times, you can squeeze even more out of the Lemon! Included are complete SQLs for examining your DSC for tuning candidates that „stayed below the Radar“ before.
E04 Db2 for z/OS Locking for Application Developers from Gareth Copplestone-Jones. All about locking from the developer’s POV. Contains Lock Size recommendations and descriptions of Locking, and Cursors. A very good read!
E07 Beginners guide to Ansible on z/OS from Sreenivas Javvaji started with the pre-reqs like Ubuntu and then adding Ansible and installing the IBM z/OS Core Collection finishing off with yaml.
E09 Access Paths Meet Coding from Andy Green. Contains a DBA view of how application developers let access paths „slide“ over time until incidents start to happen, and how to correct this by putting back „optimization“ into the development process. Extremely useful presentation for Application Developers and SQL coders!
E10 SQL Injection and Db2 – Pathology and Prevention from Petr Plavjaník. A cross platform presentation all about SQL injection and how it can bite you… A very important take away is that it is not „just“ an LUW or distributed problem. Dynamic SQL in COBOL can just as easily be injected…
E13 How Can Python Help You with Db2? From Markéta Mužíková and Petr Plavjaník. Everything you ever wondered about Python but were afraid to ask! Included an installation list explaining some of the more weird environmental variables of the pyenv.sh
E14 Use Profiles to Monitor and Control Db2 Application Context from Maryela Weihrauch. This was all about one of the, in my personal opinion, most underused features of Db2 on z/OS. They have been around for years and they enable so much e.g. Global Variables, driver upgrades, RELEASE(DEALLOCATE) / RELEASE(COMMIT) etc etc
E15 -805 Explained from Emil Kotrc. This explained the whole background of program preparation Precompile, Compile, Link and BIND. Which consistency token goes where and when is it validated?
F03 Is it worth to migrate CICS cobol app to Windows .net ? from Mateusz Książek. Naturally I am a little bit biased here, as I would always say „NO!“. However Mateusz goes on to explain the difficulty of monitoring and comparing the results. It was a bit like apples and oranges after all and he ended on a Pros and Cons slide where you must decide …
F04 COBOL abound from Eric Weyler. This was all about the remarkable life of COBOL and how it is *still* nailed to its perch! There are „new“ forms like gnuCOBOL and new front ends like VS Code and of course Zowe and Web GUIs with z/OSMF.
F07 War of the Worlds – Monolith vs Microservices from Bjarne Nelson. This session highlighted the intrinsic difficulties of going to microservices (Rest et al) in comparison to the „normal“ DBMS ACID style. Finishing with „When to use microservices and when not to!“
F08 SYSCOPY: You cannot live without it! from Ramon Menendez. Detailed everything about this very important member of the Db2 Catalog. It also covered the new things in Db2 12 and 13 as well as a quick look at how SYSIBM.SYSUTILITIES interacts with it.
F09 Playing (with) FETCH from Chris Crone. This was an informative session all about FETCH where even I learnt something … shock, horror!
F17 Explain explained from Julia Carter. This was an introduction in how to use and understand the EXPLAIN statement and its output to help in correcting badly-running SQL.
Finally Track G Daily Special (Sounds like a restaurant…) :
G03 Do I Really Need to Worry about my Commit Frequency? An Introduction to Db2 Logging from Andrew Badgley. Explained the BSDS, the Active and Archive logs and how they all interact with UOW. A recommendation here during Q&A was to COMMIT about every two seconds, and one war story was of a site that had an eight hour batch run which was then deemed to have gone rogue and was duly cancelled… It started rolling back and took a while… Db2 was then shut down – It didn’t of course… IRLM was then cancelled, Db2 came crashing down. Db2 was restarted… Hours passed as it *still* did its ROLLBACK, they cancelled it again… Then restarted and then waited hours for it to actually (re)start properly…
G17 Esoteric functions in Db2 for z/OS from Roy Boxwell. Naturally the best presentation of the EMEA *cough, cough* Could be a little bit biased here… If you wanted to know about weird stuff in Db2 for z/OS then this was your starting point. Any questions drop me a line!!!
My very own Oscar
I was also very proud, and happy, to be awarded an IBM Community Award as a „Newbie IBM Champion“ for 2022! It was at the same time as John Campbell got his for lifetime achievement and was doubly good as I first met John waaaay back in the 1980’s at Westland Helicopters PLC with DB2 1.3 on MVS/XA – Those were the days!
Please drop me a line if you think I missed anything, or got something horribly wrong. I would love to hear from you!
Hi! This month I wish to briefly delve into the inner workings of the D2b Log. The topic is very broad and complex and so this newsletter is only really skimming the surface of this topic!
What is the Log?
The Db2 Log is the central area where all data changes, plus a whole lot more, gets written away by Db2 as it does its normal work. Most shops allocate several large VSAM datasets for the Active Logs which, when full, get written off to Archive Logs.
Rules of the Log
How much Log do you need? The golden rules are all time based:
1) At least 24 hours of coverage on your Active Logs
2) At least 30 days of coverage on your Archive Logs
Any less and you could seriously run into trouble, breaking the 24 hour rule means that possibly normal ROLLBACKs might suddenly be requesting tape mounts which is not pretty and breaking the 30 days rule might put you into a world of pain when data sets get migrated off and scratched in a recovery scenario.
Take Care of Your Logs!
These Logs must be looked after and cared for as they save your company’s life on a daily and hourly basis. Normally, no-one really cares about the logs as they just „work“ and that’s it! However, the Db2 Log is actually a bit of a bottleneck these days.
Remember LOG NO?
Many years ago, Roger Miller said „LOG NO datasets will be implemented in DB2 over my dead body“ as he was pretty adament that LOG NO was a bad idea. The driver behind the requirement was just the sheer size of the logs being written by Db2 and the belief that writing fewer logs would make application faster.
How Many?
When you look at the history of Db2 you can see it started with between two and 31 active logs and between 10 and 1000 archive logs. We all thought „that will be more than enough“. Nowadays we have between two and 93 active and between 10 and 10,000 archives! Some shops rotate through their six byte RBAs in 24 hours and go through 1000’s of logs so we have grown up a little bit!
Before it Hits the Log…
Remember that there is another really important ZPARM that affects the LOG before the log is even hit – OUTBUFF it started out at a value between 40K and 4000K and is now between 400(K) and 400000(K). Just set it to the highest value you can! Db2 will always look here first before even looking at the active log and so if the data is here it is much faster than VSAM access!
Bottleneck?
Some customers were convinced that one area that was slowing down Db2 was the log write and the externalization of the data within. Roger was 100% against this but even he lost this battle and so the LOG NO space was born. However, if you ever do a ROLLBACK then the space goes into COPY pending which is horrible!
Checkpoint Charlie
The number of system checkpoints also has a direct impact on log size and usage. You must decide whether you wish to go time based (IBM-recommended way is three minutes) or transaction based – or even a mix of the two methods. I am in favour of keeping my life simple so I would always recommend the checkpoint every three minutes rule. You could argue that at „quiet times“ overnight too many checkpoints will be taken, but I counter that argument with „When was the last time you ever had a quiet time on your machine?“
Index Split?
Believe it or not, index splits seem to take up some 55% of the Db2 Log at one shop I visited. We decided to try different index pages sizes , including compression, and this all really helped in reducing the log load pressure. This has a direct effect on DASD, elapsed and CPU time which was an allround winner!
Crystal Ball?
So, how do you look into the Db2 Log? If you have no tooling then you only get the IBM stuff which is – shall we say – basic. It was here that I decided to write a little COBOL program, that I have called Db2 Archive Log Viewer for Db2 z/OS, that would read all of the Archive logs (No VSAM – keep it simple!) and handle normal non-spanned log records to give me a glimpse into what on earth Db2 was writing into the darn things!
Log HealthCheck
So what does Db2 Archive Log Viewer for Db2 z/OS then do? Well, it reads as many Archive Logs as you can give it and reports on the contents of the Logs in absolute numbers and in size. Using this data enables you to get a new view into what your Db2 system is actually doing and who is causing all your logs to be written.
Surprise!
I was pretty surprised by what I saw inside my logs and I hope you find it interesting to peer inside your logs!
If you have any ideas or desires about log datasets, feel free to email me!
This month I’m reviewing CLONE Table usage. It is one of several, what I call „esoteric“, Db2 abilities/functions that I will be running through over the coming months, plus some blogs that are either badly misunderstood, not used by anyone, or just very odd.
Attack of the Clones
Clones arrived in a blaze of glory way back in DB2 9 (remember that capital B?) and then promptly disappeared. I have had nothing to do with them – ever – and I only received one question about their usage. Until now…
What Changed?
Well, what happened, is that I was asked if our RealTime DBAExpert utility generating software worked with CLONE tables, and I had to do some quick checking in my head about *what* these things were!
How Do They Work?
So what is a CLONE Table? It is basically a duplicate table that lives in the „same“ tablespace but with a different INSTANCE. This is the first place where people make mistakes. You read a lot about renaming the VSAM LDS. That *never* happens with CLONEs. The „trick“ that IBM uses is the INSTANCE, but I am getting ahead of my self here!
In the Beginning…
Create a Database, Tablespace and a Table with a couple of indexes:
CREATE DATABASE "TESTDB" BUFFERPOOL BP0 INDEXBP BP0 STOGROUP SYSDEFLT ; COMMIT ; CREATE TABLESPACE "TESTTS" IN "TESTDB" USING STOGROUP SYSDEFLT PRIQTY -1 SECQTY -1 ERASE NO FREEPAGE 5 PCTFREE 10 GBPCACHE CHANGED TRACKMOD YES LOG YES DEFINE YES DSSIZE 1 G MAXPARTITIONS 1 BUFFERPOOL BP0 LOCKSIZE ANY LOCKMAX SYSTEM CLOSE YES COMPRESS NO MAXROWS 255 SEGSIZE 32 ; COMMIT ; CREATE TABLE BOXWELL.TEST_BASE (COL1 CHAR(12) NOT NULL ,COL2 INTEGER NOT NULL ,COL3 INTEGER NOT NULL) IN TESTDB.TESTTS ; COMMIT ; CREATE UNIQUE INDEX BOXWELL.TEST_BASE_IX1 ON BOXWELL.TEST_BASE (COL1, COL2, COL3) USING STOGROUP SYSDEFLT PRIQTY -1 SECQTY -1 ERASE NO FREEPAGE 5 PCTFREE 10 GBPCACHE CHANGED BUFFERPOOL BP0 CLOSE YES COPY NO ; COMMIT ; CREATE INDEX BOXWELL.TEST_BASE_IX2 ON BOXWELL.TEST_BASE (COL2, COL3) USING STOGROUP SYSDEFLT PRIQTY -1 SECQTY -1 ERASE NO FREEPAGE 5 PCTFREE 10 GBPCACHE CHANGED BUFFERPOOL BP0 CLOSE YES COPY NO ; COMMIT ;
Insert some data:
INSERT INTO BOXWELL.TEST_BASE VALUES ('A', 1 , 2); INSERT INTO BOXWELL.TEST_BASE VALUES ('B', 1 , 2); INSERT INTO BOXWELL.TEST_BASE VALUES ('C', 1 , 2); INSERT INTO BOXWELL.TEST_BASE VALUES ('D', 1 , 2); INSERT INTO BOXWELL.TEST_BASE VALUES ('E', 1 , 2); INSERT INTO BOXWELL.TEST_BASE VALUES ('F', 2 , 2); INSERT INTO BOXWELL.TEST_BASE VALUES ('G', 2 , 2); INSERT INTO BOXWELL.TEST_BASE VALUES ('H', 2 , 3); INSERT INTO BOXWELL.TEST_BASE VALUES ('I', 2 , 3); INSERT INTO BOXWELL.TEST_BASE VALUES ('J', 2 , 3); COMMIT ;
What Says RTS?
First, make sure the real-time statistics (RTS) have all been externalized:
-ACCESS DATABASE(TESTDB) SPACENAM(*) MODE(STATS)
Then run a little SQL:
SELECT * FROM SYSIBM.SYSTABLESPACESTATS WHERE DBNAME = 'TESTDB' ; SELECT * FROM SYSIBM.SYSINDEXSPACESTATS WHERE DBNAME = 'TESTDB' ;
You should see one row from SYSTABLESPACESTATS with 10 TOTALROWS and 10 REORGINSERTS etc. and two rows from SYSINDEXSPACESTATS with 10 TOTALENTRIES and 10 REORGINSERTS etc. Now we have what I call the „base“ table.
Finally the Boss Guy – SYSTABLESPACE. Here is where the access is controlled using, yet again, INSTANCE and its good friend CLONE:
SELECT * FROM SYSIBM.SYSTABLESPACE WHERE DBNAME = 'TESTDB' ;
--+---------+--
INSTANCE CLONE
--+---------+--
1 Y
This is showing you all the information you need. The current base table is still the original table and this tablespace is in a „clone relationship“ – slightly better than „it’s complicated“ but close!
Test Select
Run this to see what you get back:
SELECT COUNT(*) FROM BOXWELL.TEST_BASE ;
SELECT COUNT(*) FROM RINGO.AARDVARK ;
You should get ten from the first count and zero from the second.
So What Is the Point?
Now we, finally, get to the raison d’être of CLONEs. The idea is that using table name ringo.aardvark you can INSERT data, perhaps very slowly over a period of days, into the CLONE TABLE and the application is not aware of and cannot be affected by it. Once the INSERT processing is completed you may then do the EXCHANGE DATA command to instantaneously swap the tables around. OK, it must actually just do a one byte update of the INSTANCE column in the SYSTABLESPACE, but I digress…
Here’s How it Looks
EXCHANGE DATA BETWEEN TABLE BOXWELL.TEST_BASE
AND RINGO.AARDVARK
;
COMMIT ;
Now do those COUNT(*) SQLs again:
SELECT COUNT(*) FROM BOXWELL.TEST_BASE
---------+---------+---------+--------
0
DSNE610I NUMBER OF ROWS DISPLAYED IS 1
SELECT COUNT(*) FROM RINGO.AARDVARK
---------+---------+---------+--------
10
DSNE610I NUMBER OF ROWS DISPLAYED IS 1
Whoopee! You can see that the table name has not changed but all the data has! This is pretty cool!
Downsides …
Never a day without pain, my mother used to say, and CLONEs come with a bunch of pain points!
Pain Point Number One
Reduced utility support. You can only run MODIFY RECOVERY, COPY, REORG (without inline statistics!) and QUIESCE against these. Why? Because there is only one set of catalog statistics for them. A RUNSTATS would destroy all of the data for *both* objects and the current object access paths might all go south; further, you absolutely *must* add the keyword CLONE to the utility control cards. You *cannot* rely on LISTDEF to do this for you and it is documented:
This utility processes clone data only if the CLONE keyword is specified. The use of CLONED YES on the LISTDEF statement is not sufficient.
but people still miss this and then *think* they are working with their clones but they are not! This can get very embarrassing…
Pain Point Number Two
You must remember to RUNSTATS the „new“ base after the EXCHANGE has been done. The RTS is always in step, the Catalog is probably way out of line…
When You Are Quite Finished
Once a CLONE table is no longer required you can easily drop it but naturally not with a DROP but with another ALTER statement:
ALTER TABLE BOXWELL.TEST_BASE
DROP CLONE
;
COMMIT ;
Pain Point Number Three
The problem here is not that bad, but, depending on when you do the DROP CLONE, your „base“ could be the instance two! You, and your vendors, must make sure your Db2 and non-Db2 utilities are happy with this state of affairs!
Yep, we are in the clear! Our software does indeed support these esoteric beasts.
Over To You!
Do you use CLONEs? If so, why? Any war stories or is everything hunky dory?
As usual I would love to hear from you!
TTFN,
Roy Boxwell
Updates
I got quite a few updates about clones:
DDL Disaster
One of the major issues that I missed was another pain point: DDL Changes. These are really nasty as you must throw away your clone before you can do the ALTER and then recreate the CLONE relationship.
Commands
I also did not mention that various commands also need the CLONE keyword to be applied to CLONE spaces. For example -START DATABASE(xxx) SPCENAM(yyy) CLONE
We have „GIVEn“ various free-of-charge Use Cases from our SQL WorkloadExpert for Db2 z/OS like:
1 Index Maintenance Costs
2EXPLAIN Suppression
3BIF Usage
Limited free-of-Charge Db2 Application
This Program started in Europe, during our 30th anniversary was such a success, that it is now being Extended for the benefit of North American Db2 z/OS sites.
SQL WorkloadExpert™ for Db2 z/OS (WLX) contains several “Use Cases”. We provided three of them, free of charge, for one month to different sites.
In return, we received their results. We’d like to share this inspiring experiences with you now.
Inspiring experiences
We TAKE the anonymized results for research
and will communicate with the local User Groups for discussions
Änderungen bei der STRING Formatierung von Decimal Data bei der CHAR und VARCHAR built-in Funktion und bei der CAST Spezifikation mit CHAR und VARCHAR Ergebnis Typen sowie UNSUPPORTED TIMESTAMP STRINGs.
Wo sind die BIFs? Und wie können wir in Zukunft problemlos mit BIFs leben? Wege aus der mangelnden Aufwärtskompatibilität bei der Migration von Db2 Versionen
(11min.) Trap and correct the BIFs that will cause belly-ache one day soon
BIF Usage Video
Um unsere Webseite für Sie optimal zu gestalten und fortlaufend verbessern zu können, verwenden wir Cookies. Lehnen Sie Cookies ab, stehen einige Funktionen der Website nicht zur Verfügung. Weitere Informationen hierzu erhalten Sie in unserer Datenschutzerklärung.AkzeptierenAblehnenDatenschutzerklärung