

This month I wish to chat about Db2 on z/OS BUFFERPOOLs and their misuse throughout the world.
One Size Fits All?
Bufferpool tuning tools have been available for decades, but I had the feeling that the usage has dropped off these days and the cut-and-paste generation has started to cause, shall we say, problems in the pool!
Oldies But Goldies
The standard set of rules *always* starts with „Thou shalt not pollute the pool!“
The idea here is very simple: Keep the Db2 Directory and Catalog apart from „user data“ – the access patterns and sizes for the Directory and Catalog are different than normal user data and you do *not* want to mix’n’match here!
Keep Indexes and Tablespaces Apart
Just like teenagers, keeping them apart can help a lot! The typical access patterns for indexes (especially compressed indexes) and user data are always different. These should very rarely share a pool!
Know Your Access Types!
Are you a sequential access or a random access type? The difference is important – Db2 tracks all the different access types, so it is not that hard to see whether or not sequential access is pushing out your index random access leaf pages, for example!
Sort??
Sort and work spaces should also go into their own pool as sort tends to be 100% sequential.
What About Prefetch Minimum Size??
To activate a good prefetch chain, your bufferpool must meet minimum size limits. Smaller than the minimum size and your prefetch usage goes horribly wrong.
PGFIX – Yes
This has been described as „the no brainer No. 1“ as Db2 basically *requires* enough memory for the BPs not to page, and so you can save a ton of CPU by setting PGFIX(YES) – Note that this is not same as setting PGSTEAL(NONE) !
LOB and XML Spaces
These are the ugly ducklings under the tablespace family tree and both should *not* be in any normal BP as the access methods for them are 100% different!
Check Again!
So now go and check your BUFFERPOOLs and see if you have broken any of the above seven BP commandments? I am 100% certain that you have…
Are You on the Same Page as Me?
If you have PAGE INs then that is normally, to quote IBM, sub-optimal. If the number of PAGE INs is greater than the BP size it is very, very bad indeed!
What About GROUP BUFFERPOOLS?
Always worth checking these and seeing if the Cross Invalidations is > 10% or if the storage counters are above zero. Also, check what your current RATIO is… Might be way too low or way too high!
Bufferpool Thresholds?
You do know your BP thresholds, don’t you?
Immediate write – 97.5% – Very very bad.
Data Management – 95% – Bad.
Prefetch disabled – 90% – Not good.
Then the Thresholds that You Can Set:
Sequential Steal threshold (VPSEQT) – 80% range 0 – 100. If zero then most, if not all, prefetch is switched off and no parallel prefetch is allowed.
Virtual Parallel Sequential threshold (VPPSEQT) – 50% range 0 – 100, zero means no parallel.
Deferred Write threshold (DWQT) 30% range 0 – 90.
Vertical Deferred Write threshold – 5% range 0 – 90 as a percentage, and if the first value is zero then the second value is absolute number of pages in the range 0 – 9999.
Sequential Steal
This is how much of the BP can be taken over by purely sequential data access pages. For SORT pools 90+ is fine. If you then see SYNC READ I/O going up slowly, lower back towards 80.
Deferred Write
The DWQT is for the complete bufferpool. If that percentage is hit, then an asynchnronous task is kicked off to write updated pages to disk, until it hits 10% less than this threshold. Now for some objects that is too large a number and can lead to flooding, so we also have the VDWQT which has the same control but at the object level. You specify how many pages per object can be updated before Db2 kicks off async writing.
Metrics …
In the beginning was the Hit Ratio but it is a bit of a red herring these days. Much better is to check the average page residency times. If the data is kicked out of the BP before 600 seconds it is probably time to do some changes! There are tons of other metrics but I will not go into the nitty gritty here!
Real World Results!
I asked a few of our customers do some -DISPLAY BUFFERPOOL commands and then send me the data. I then did an analysis of the data and was a little bit surpised at the results:
Management summary: Every customer has bufferpool problems, even those that swore everything was green at their site!
In the following graphics everything that does not have a green/white background is not good (Apart from the two Intensity heat columns where only the red ones are worth checking!)
Examples
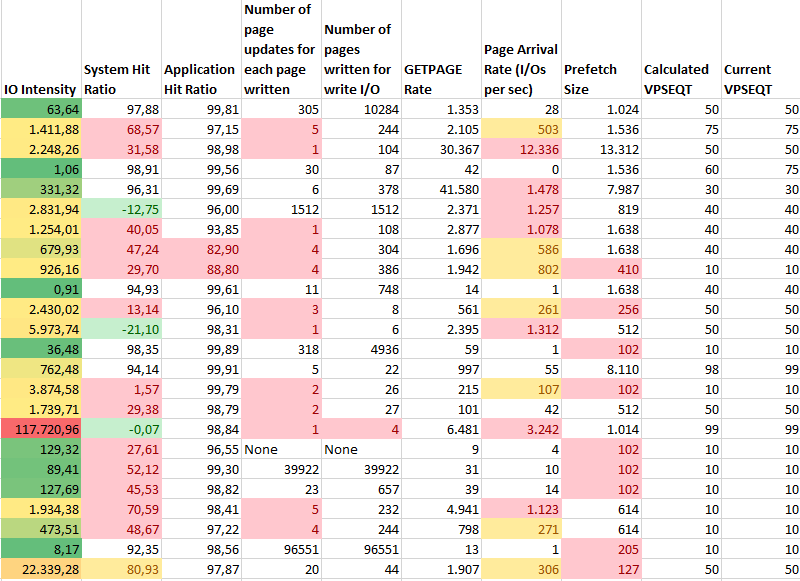
Here you can see it is not that bad. The hit ratios are not good, (the negative Hit Ratio is caused by serious prefetch activity!) and the number of writes is below expectations, but the prefetch size is the big worry here! One good point is the near perfect VPSEQT compared to the calculated one. Very good!
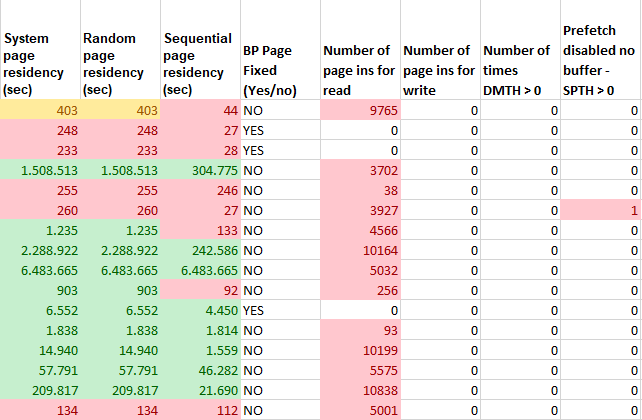
The number of PAGE INs here is very bad but is caused, obviously, by the PAGEFIX(NO) defs.

The VDWQT per second rate is well above what it should be, prefetch size is very wrong and the Page Arrival rate is high!
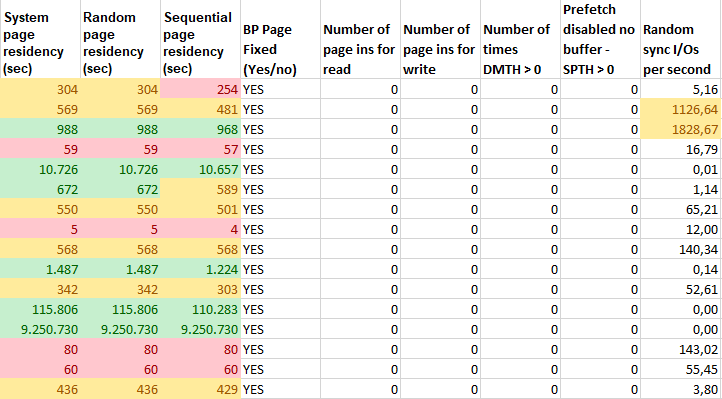
The residency times are at both extremes here!
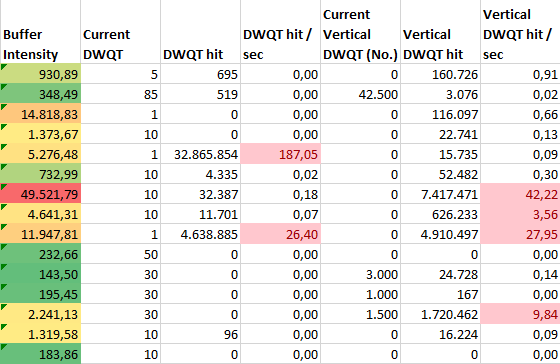
Here, there are way to many DWQT and VDWQT being hit per second.
And Finally
So what can you do? Well, you can contact me and I will tell you which commands to issue. Then I can send you back a PDF with the details above. Please note that I can only process the first ten requests! But I will allow five from EMEA and five from the USA to make the timezones a bit fairer!
Future Trends and Directions
We’re currently extending SQL WorkloadExpert with it’s Zowe front end, so that you then have the chance to fix things with a couple of clicks and even play around with simulated buffer pool sizing! Below I’m sharing a sneak preview:

and then drilling down:
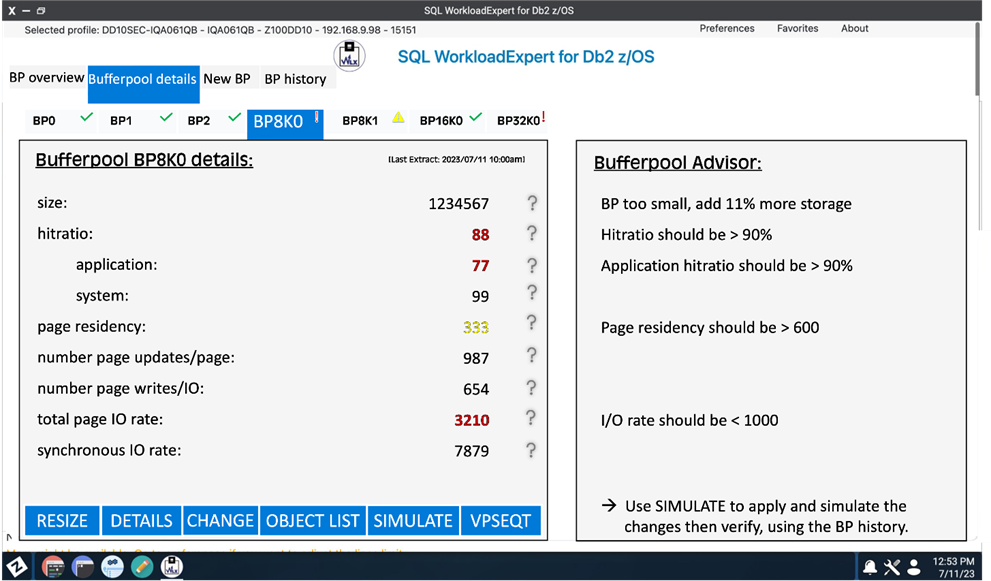
Simulated?
I do hope that you are aware of the „simulated bufferpool“ feature and have at least looked at it? It is one of the best things in years to have happened to bufferpool tuning!
So whaddy’all think? Is it time to go back to the drawing board with Bufferpool tuning or are yours all 100% correct?
I would love to hear from you!
TTFN
Roy Boxwell