EXPLAIN has been with us since DB2 V2.1 and, as I have previously written in older newsletters, (2019-03 EXPLAIN data review and 2012-11 EXPLAIN table maintenance), it has gotten bigger and better over the years. In this newsletter, I wish to quickly bring everyone up-to-date, based on my two older newsletters, and then discuss the usage of CTE Opthints.
Up to speed
Back in 2012, I listed out the tables EXPLAIN can use and ended with Db2 10, so first up are the new and changed tables for Db2 11 and Db2 12:
Db2 11
| PLAN_TABLE | Now with 66 columns |
| DSN_COLDIST_TABLE | |
| DSN_DETCOST_TABLE | |
| DSN_FILTER_TABLE | |
| DSN_FUNCTION_TABLE | |
| DSN_KEYTGTDIST_TABLE | |
| DSN_PGRANGE_TABLE | |
| DSN_PGROUP_TABLE | |
| DSN_PREDICAT_TABLE | |
| DSN_PREDICATE_SELECTIVITY | New but input for the BIND QUERY command only! |
| DSN_PTASK_TABLE | |
| DSN_QUERYINFO_TABLE | Two LOB tables as well |
| DSN_QUERY_TABLE | One LOB table as well |
| DSN_SORTKEY_TABLE | |
| DSN_SORT_TABLE | |
| DSN_STATEMENT_CACHE_TABLE | Only for DSC |
| DSN_STATEMNT_TABLE | |
| DSN_STAT_FEEDBACK | New table containing RUNSTATS recommendations when EXPLAIN is executed. |
| DSN_STRUCT_TABLE | |
| DSN_VIEWREF_TABLE |
Db2 12
| PLAN_TABLE | Now with 67 columns |
| DSN_COLDIST_TABLE | |
| DSN_DETCOST_TABLE | |
| DSN_FILTER_TABLE | |
| DSN_FUNCTION_TABLE | |
| DSN_KEYTGTDIST_TABLE | |
| DSN_PGRANGE_TABLE | |
| DSN_PGROUP_TABLE | |
| DSN_PREDICAT_TABLE | |
| DSN_PREDICATE_SELECTIVITY | |
| DSN_PTASK_TABLE | |
| DSN_QUERYINFO_TABLE | Two LOB tables as well |
| DSN_QUERY_TABLE | One LOB table as well |
| DSN_SORTKEY_TABLE | |
| DSN_SORT_TABLE | |
| DSN_STATEMENT_CACHE_TABLE | Only for DSC |
| DSN_STATEMNT_TABLE | |
| DSN_STAT_FEEDBACK | |
| DSN_STRUCT_TABLE | |
| DSN_VIEWREF_TABLE |
So you can see, that not a lot really happened in Db2 12 as far as any new EXPLAIN tables, but the one big change was the new column sprinkled throughout all of them: PER_STMT_ID
Something new
PER_STMT_ID BIGINT NOT NULL The persistent statement identifier for SQL statements in Db2 catalog tables.
For example, this column corresponds to the following catalog table columns that identify
SQL statements:
• STMT_ID in SYSIBM.SYSPACKSTMT, for SQL statements in packages.
• SDQ_STMT_ID in SYSIBM.SYSDYNQUERY, for stabilized dynamic SQL statements.
This column makes it *much* easier to track your mix of dynamic and static SQL all through the system!
CTE Opthints
I was using one of these the other day and the customer I was working with was amazed to see what it is and how it works. As in all things to do with OPTHINTs, caution must always be used! The best OPTHINT is no OPTHINT!
In the Beginning
Many, many years ago, sometime around DB2 V8, I found a CTE Opthint documented in the internet and thought “Wow! That is the future of hints!” Then they completely disappeared… try doing a google search and you will see what I mean. The cool thing is – They still work! I do not know for how long, but they still work in Db2 12 FL507 at least.
Time to Test
First create a couple of test table candidates and one index:
CREATE TABLE BOXWELL.T1 (C1 CHAR(8) NOT NULL
,C2 CHAR(8) NOT NULL
,C3 SMALLINT NOT NULL);
CREATE TABLE BOXWELL.T2 (C1 CHAR(8) NOT NULL
,C2 CHAR(8) NOT NULL
,C3 SMALLINT NOT NULL);CREATE INDEX INDX1_T2 ON T2 ( C1 ) CLUSTER ;
The SQL of interest is:
SELECT T1.*
FROM T1
, T2
WHERE T1.C1 = T2.C1
;
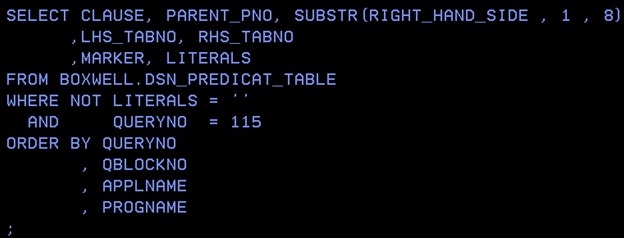
So first you do a normal EXPLAIN and get this output:
---------+---------+---------+---------+---------+---------+---------+---------+---------+-------- LINE QNO PNO SQ M TABLE_NAME A PA CS INDEX IO UJOG UJOGC P ---------+---------+---------+---------+---------+---------+---------+---------+-------- 01000 01 01 00 0 T1 R 00 N ---- ---- S 01000 01 02 00 1 T2 I T 00 INDX1_T2 Y -Y-- ---- S
So Db2 accesses T1 first with a tablespace scan (A = R) and then uses the index to access T2. Now add the CTE to the front so the SQL looks like:
WITH DSN_INLINE_OPT_HINT
(TABLE_CREATOR
, TABLE_NAME
, ACCESS_TYPE
, ACCESS_CREATOR
, ACCESS_NAME
, JOIN_SEQ) AS
(VALUES (NULL
, NULL
, 'INDEX'
, NULL
, NULL
, NULL)
)
SELECT T1.*
FROM T1
, T2
WHERE T1.C1 = T2.C1
; Rules, Rules, Rules
The golden rules of CTE Opthint are that the CTE must be the first CTE, and it must be called DSN_INLINE_OPT_HINT, your ZPARM OPTHINTS must be set to YES to allow them, of course. Just include the columns and the rows you actually need. Every additional column or row is one more step towards optimizer disapproval and the CTE Opthint being ignored.
In the example above, the value NULL is a wild card short hand for all values and that row is simply telling the optimizer “If nothing else is found try and enforce INDEX access”.
So now the access path looks like:
---------+---------+---------+---------+---------+---------+---------+---------+---------+-------- LINE QNO PNO SQ M TABLE_NAME A PA CS INDEX IO UJOG UJOGC P ---------+---------+---------+---------+---------+---------+---------+---------+-------- 01001 01 01 00 0 T2 I 00 INDX1_T2 Y ---- ---- S 01001 01 02 00 1 T1 R T 00 N -Y-- ---- S
Seeing double?
As you can see, Db2 now uses the index first. So what if you had two indexes?? Create an index on the first table:
CREATE INDEX INDX1_T1 ON T1 ( C1 ) CLUSTER ;
Now the “normal” SQL EXPLAIN shows:
---------+---------+---------+---------+---------+---------+---------+---------+---------+-------- LINE QNO PNO SQ M TABLE_NAME A PA CS INDEX IO UJOG UJOGC P ---------+---------+---------+---------+---------+---------+---------+---------+-------- 02000 01 01 00 0 T1 R 00 N ---- ---- S 02000 01 02 00 1 T2 I T 00 INDX1_T2 Y -Y-- ---- S
We are back to tablespace scan on T1 and then IX on T2. Now, using the CTE with just INDEX (That is the one we just used) gives you:
---------+---------+---------+---------+---------+---------+---------+---------+---------+-------- LINE QNO PNO SQ M TABLE_NAME A PA CS INDEX IO UJOG UJOGC P ---------+---------+---------+---------+---------+---------+---------+---------+-------- 02001 01 01 00 0 T1 I 00 INDX1_T1 N ---- ---- 02001 01 02 00 1 T2 I 01 INDX1_T2 Y ---- ----
So, we have now got double index access (which is what we wanted!) What about trying to push T2 up to the first table to be used? Just add a second row in the CTE like this:
WITH DSN_INLINE_OPT_HINT
(TABLE_CREATOR
, TABLE_NAME
, ACCESS_TYPE
, ACCESS_CREATOR
, ACCESS_NAME
, JOIN_SEQ) AS
(VALUES (NULL
, NULL
, 'INDEX'
, NULL
, NULL
, NULL)
,(NULL
, 'T2'
, NULL
, 'BOXWELL'
, 'INDX1_T2'
, 1 )
)
SELECT T1.*
FROM T1
, T2
WHERE T1.C1 = T2.C1
; And the output now changes to be this:
---------+---------+---------+---------+---------+---------+---------+---------+---------+-------- LINE QNO PNO SQ M TABLE_NAME A PA CS INDEX IO UJOG UJOGC P ---------+---------+---------+---------+---------+---------+---------+---------+-------- 02002 01 01 00 0 T2 I 00 INDX1_T2 Y ---- ---- S 02002 01 02 00 2 T1 I 00 INDX1_T1 N ---- ----
Isn’t that cool?
I think these are very, very handy items and are a crucial extra piece in the puzzle of “tipping point” SQLs. CTE Opthints work for both Dynamic and static SQL by the way.
One final bit of info about these CTE Opthints: If defined OK and accepted by EXPLAIN you will get:
DSNT404I SQLCODE = 394, WARNING: USER SPECIFIED OPTIMIZATION HINTS USED DURING ACCESS PATH SELECTION
DSNT418I SQLSTATE = 01629 SQLSTATE RETURN CODE
DSNT415I SQLERRP = DSNXOPCO SQL PROCEDURE DETECTING ERROR
DSNT416I SQLERRD = 20 0 4000000 1143356589 0 0 SQL DIAGNOSTIC INFORMATION
DSNT416I SQLERRD = X'00000014' X'00000000' X'003D0900' X'44263CAD'
X'00000000' X'00000000' SQL DIAGNOSTIC INFORMATION
DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 0 If you get something wrong you will get *no* message SQLCODE +394 (This happens if your column names are invalid for example), and if the SQL Opthint is *not* used you get this SQLCODE output:
DSNT404I SQLCODE = 395, WARNING: USER SPECIFIED OPTIMIZATION HINTS ARE INVALID (REASON CODE = 'xx'). THE OPTIMIZATION HINTS ARE IGNORED
DSNT418I SQLSTATE = 01628 SQLSTATE RETURN CODE
DSNT415I SQLERRP = DSNXOOP SQL PROCEDURE DETECTING ERROR
DSNT416I SQLERRD = 20 0 4000000 1142580885 0 0 SQL DIAGNOSTIC INFORMATION
DSNT416I SQLERRD = X'00000014' X'00000000' X'003D0900' X'441A6695'
X'00000000' X'00000000' SQL DIAGNOSTIC INFORMATION
DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 0 Tipping points
We all have had SQLs that run fine for years and then, normally after a RUNSTATS, the order of the tables swaps… this is not really seen by anyone until the SQL starts performing really badly! If you have one of these “tipping point” SQLs you can now simply “lock it in” with a simple CTE at the start of the SQL.
Columns of interest
In my examples I only used a few of the allowable columns in a CTE Opthint. Here’s a list of as many as I have found:
| Column Name | Remarks |
| TABLE_CREATOR | NULL for all |
| TABLE_NAME | NULL for all |
| CORRELATION_NAME | Needed if duplicate table names |
| ACCESS_TYPE | RSCAN, INDEX, INLIST, MULTI_INDEX |
| ACCESS_CREATOR | Index Schema, NULL for all |
| ACCESS_NAME | Index Name, NULL for all |
| JOIN_SEQ | Join sequence number. 1 for first table. |
| JOIN_METHOD | NLJ, SMJ, HYBRID |
| PARALLELISM_MODE | CPU, IO, SYSPLEX |
| ACCESS_DEGREE | Degree of required parallelism |
| JOIN_DEGREE | Degree of required parallelism |
| TABNO | Normally never required. If used take the number from the PLAN_TABLE |
| QBLOCKNO | Normally never required. Must be used if duplicate table names and correlation Ids. Take the value from the PLAN_TABLE |
| PREFETCH | S or L. Sequential or List Prefetch to be used. From this column on I have never used them! |
| QBLOCK_TYPE | |
| MATCHING_PRED | |
| HINT_TYPE | |
| OPT_PARM |
As usual, if you have any questions or ideas please drop me a line!
TTFN,
Roy Boxwell
Update: One of my readers pointed out that he uses these beasts and even had to open a PMR. Here I quote:
“I learned the hard way that CTE Hints were not honored when you did a rebind with APREUSE(WARN). I reported this to IBM, they did fix it with UI68523, you want to be sure you have that.”
Another reader found that I had cut-and-pasted the DDL a bit too fast so all of the DDL got corrected where it was wrong (The table create and the second index create)
Yet another sent me an updated column list and so have done some changes to the list of columns used in the table.
It is Now Official!
IBM just released, on the 2022-06-24, an update on the AHA page DB24ZOS-I-717 that CTE inline hints are now supported with a pointer to the APAR PK04574 (Closed in 2015!!!). Now we must just wait for the docu update I guess!