

Do you have the DDL anywhere?
Was there a “recent” image copy or disk back-up? Who can you call for help?
The newsletter title this month is really nothing to do with the film “Marathon Man”, but sometimes backup and recovery can feel just like having your teeth drilled… Anyway, the title is actually meant to get you to think again about your site’s back-up and recovery definitions—specifically that age-old chestnut about “accidently” dropped objects.
RECOVER from DROP?
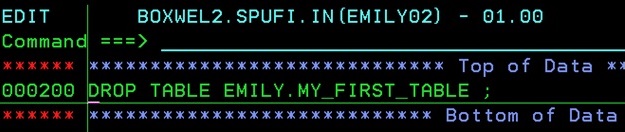
I saw in LISTSERV a discussion about recovering from dropped tables and tablespaces. It is a pretty horrible situation when you realize that, you just confirmed the drop of a test table to then suddenly see that as your finger is descending towards the ENTER key that it is, in fact, a different name…
DDL and Back-ups Handy?
Normally, at this point, the air is filled with colorful language and interesting local metaphors. Once it has calmed down a bit the real work starts: Do you have the DDL anywhere? Was there a “recent” image copy, or a disk back-up? Who can you call for help?
Mirror Mirror on the wall
Remember that mirroring etc. will not help you as the DROP has also been successfully mirrored. So within a moment, the data was also dropped at your disaster recovery site. (Argh!)
Newbies then start looking in SYSIBM.SYSCOPY for the last image copies, while us grey-haired oldies more mature experts start looking in production control copy libraries and BETA92!
The heat is on!
At this point a couple of things happen: The telephone starts ringing and a manager-type person materializes to ask annoying questions all the time. Typically: “How long will it take to get the data back?”
Now you have two possibilities:
1.You are in luck! Someone somewhere extracted all the DDL for the table(s) with DBID, PSID, and OBID(s) so you could generate a DSN1COPY job from the last found Image Copy dataset
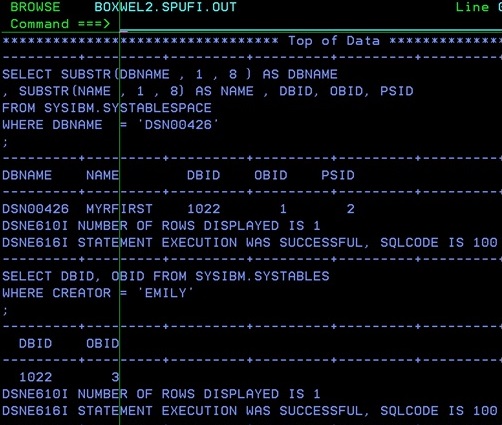
2. You are *not* in luck! You have no idea how the table looks, and you cannot see if anyone ALTERed it in the last five years or so.
Crashed and Burned
If you are in position 2, it is now a good time to update your CV and make sure your desk is neat and tidy… Now you might have access to some nifty third party vendor tools, but for that you must at least have the dataset name of the last Image Copy and—of course—the third party tool itself! Or the ability to read the DB2 log and “resurrect” the table defs from there—Not a pretty place to go I assure you!
Back up that chain of thought for a Moment
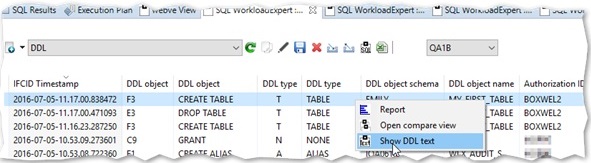
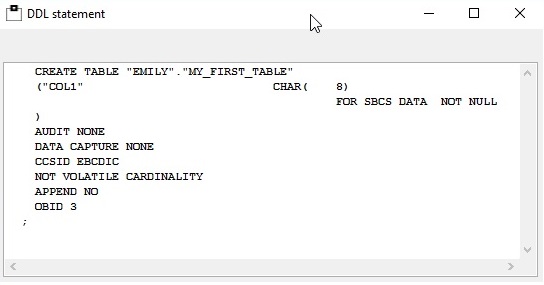
So let’s rewind and imagine that you are doing this all differently… What about beginning today with an extract of all the DDL on your system? Then capture all of the IFCID 62’s that show any DDL changes. Going further: what about getting all of the IFCID 220’s to get dataset allocations correlated with Utility IDs and DBIDs and PSIDs.
Imagine what you could then do?
Wow! Cavalry over the hill
Yep, you have a ”history” of all the DDL that has happened on your machine right up to the point when your object was DROPed *and* you have the dataset name(s) of the last image copies as well as all the internal IDs to enable a successful DSN1COPY job complete with OBID translation! Cool huh? So suddenly you are now a hero instead of a villain!
DIY or Buy in?
So much for the theory – What about in practice? Well you can write it all yourself or you could use this as a sort of useful side effect from our WorkloadExpert (WLX) software which has all this built in! We already get all these IFCIDs, we already have a DDL Generator bundled with the WLX software for the Audit Use Cases and so it really kills two birds with one stone!
Restricted movement?
Now, of course, you could argue:“Wait! I have RESTRICT ON DROP set for all my productive tables!” Now this works really well for accidental drops, but I have seen lots of places where it should be used but was in fact forgotten. How can you check? Run this little SQL to validate that what you think is true really is true:
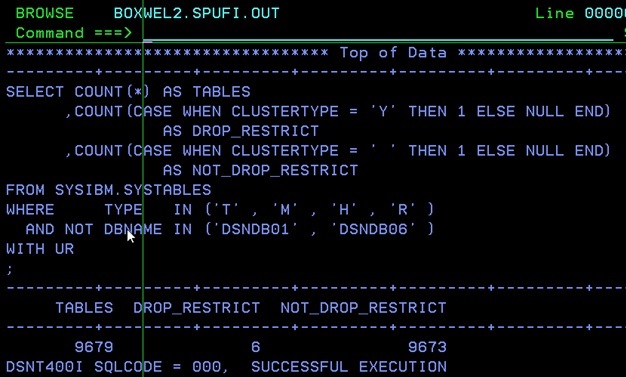
SELECT COUNT(*) AS TABLES
,COUNT(CASE WHEN CLUSTERTYPE = 'Y' THEN 1 ELSE NULL END)
AS DROP_RESTRICT
,COUNT(CASE WHEN CLUSTERTYPE = ' ' THEN 1 ELSE NULL END)
AS NOT_DROP_RESTRICT
FROM SYSIBM.SYSTABLES
WHERE TYPE IN ('T' , 'M' , 'H' , 'R' )
AND NOT DBNAME IN ('DSNDB01' , 'DSNDB06' )
WITH UR
;
I hope the results don’t have you feeling like Dustin Hoffman in the movie.
As usual any questions or comments are welcome,
TTFN Roy Boxwell