A really brief blog this month, as I found something out while playing with buffer pool tuning (I have no hobbies!)
Buffer Pools …
There has been a long debate down the years about buffer pool management. How big should they be? How many should you have? Which parameters for which type? And so on. I have written numerous blogs, held IDUG Presentations and discussed myriad times with colleagues and customers about this topic.
Something New???
I found something new! Well, new to me anyways!!!
There was a trend a few years ago, called “big memory” where people were encouraged to recombine many data-sharing members downwards so you went from a 14 way to eight way or six way to four way. This was then backed up with more DBATs and expanded buffer pools. The argument was pretty convincing: Let Db2 do the magic!
Too Much Work!
You, as a puny human, have no chance of really knowing what is going on. So just splitting the buffer pools at the highest possible level is all you can actually reasonably do! The argument went that it is easiest to go for around 9 – 10 buffer pools.
DISPLAY GROUPBUFFERPOOL Done on a Regular Basis?
Of course you do!!!
What I found out recently, is the ominous counter in message DSNB415I titled “PREFETCH DISABLED NO READ ENGINE”. Nowadays, each Db2 subsystem/member of a datasharing system has 900 read engines but before, it was split out in 14 or eight sub-systems and is now being used in far fewer.
Zero Counter No More!
This counter was *always* zero whenever and wherever I checked, until last week… Now I see PREFETCH DISABLED NO READ ENGINE on a regular basis. There is a great blog from Robert Catterall.
In the environments I am looking at, they also have PREFETCH DISABLED NO BUFFER occurrences and well over 100 I/Os /second, so it does indeed mean trouble!
Time to Tune!
All you can do here is:
Check your VPSEQT and see if you can nudge it up a bit.
Throw some memory at the problem by increasing the VPSIZE and hope that the requested pages are then found in the buffer pool.
Move smaller objects into PGSTEAL(NONE) buffer pools thus requiring no PREFETCH.
As a last gasp, try and tune the SQL to not use PREFETCH as a method – very tricky of course!
Keep on Truckin’
But let’s be honest for a minute, if you have 900 read engines all humming along then your system is really running under pressure and you should *expect* to get this counter, I guess!
This month I wish to share an interesting voyage of discovery to do with TIMESTAMP calculations.
How Interesting …
It all started decades ago, when I wanted to find out how many microseconds there were between two timestamps. A simple idea for a trace in various programs which, when analyzed, could highlight problematic code paths.
Use DISPLAY Stupid!
Just DISPLAY the current timestamp at the start of each SECTION. The trace analysis program would then simply subtract two timestamps – et Voila! You have a difference!
Nope … That Fails
Well, I found out very quickly that math on TIMESTAMPs does *not* work like that! What you actually get is a “duration” which, in my humble opinion, is worthless! Here’s an example:
SELECT TIMESTAMP('2023-12-21-15.06.40.120234') -
TIMESTAMP('2023-12-21-15.06.40.120034')
FROM SYSIBM.SYSDUMMY1 ;
---------+---------+---------+---------+--------
---------+---------+---------+---------+--------
.000200
Looks good doesn’t it? Exactly 200 microseconds – as it should be.
Now look at this example:
SELECT TIMESTAMP('2023-12-21-15.06.41.120234') -
TIMESTAMP('2023-10-22-17.08.55.130234')
FROM SYSIBM.SYSDUMMY1 ;
---------+---------+---------+---------+--------
---------+---------+---------+---------+--------
129215745.990000
What?
Yep, what the calculation does is really “subtract”… What you get is a decimal 14 containing the YYYY (leading zeroes blanked of course!) years, MM months, DD days HHMMSS then a decimal point and then your usual six digits for microseconds.
Not Good!
This, for me, was not actually usable! So, what I did, was then extract all the fields multiplying by the different values and adding them all together to get a SECONDS field. This gave me what I wanted but was a bit messy.
Months?
Whoever dreamed up the western calendar obviously was not a programmer! 31, 30, 28 sometimes 29 days in a month but then not always… The days in month has been, and always will be, a real PITA. However, IBM Db2 has a nice Built-in Function (BiF) called DAYS (not DAY – That just extracts the day portion of the calendar!)
DAYS ( expression ) – The result is 1 more than the number of days from January 1, 0001 to D, where D is the date that would occur if the DATE function were applied to the argument.
All in UTC and this is *very* handy as it bypasses the days-in-the-month problem completely!
Armed with this it made the COBOL code simpler and better.
TIMESTAMPDIFF to the Rescue!
Then in Db2 V8 came a new BiF – TIMESTAMPDIFF – will it be our savior?
When it was announced I thought: Wow! This is great – it will do all the work for me – just tell it what you want as output and give it two timestamps and you are done!
The problem is in the first sentence of the docu that most people do not bother to read:
The TIMESTAMPDIFF function returns an estimated number of intervals of the type that is defined by the first argument, based on the difference between two timestamps.
Seconds is Good?
Naturally, I used 2 (to get seconds) as the numeric-expression and, to begin with, was a happy bunny with the results.
Guestimate?
Then I noticed that all was not well in the world of TIMSTAMPDIFF and that the “estimated” number can be difficult to judge! The problem gets clearer when you review the “assumptions” list at the end of the docu:
The following assumptions are used in estimating a difference:
One year has 365 days
One year has 52 weeks
One year has 12 months
One month has 30 days
One day has 24 hours
One hour has 60 minutes
One minute has 60 seconds
Now we all know that this is not true… Not all years have 365 days or even 52 weeks and nearly all months do not have 30 days! Now in my trace program it was just a bit irritating, but if you are using TIMESTAMPDIFF believing you really get the number of DAYS between two dates then it is time to think again!
Seeing is Believing
Here’s an example showing where it first works fine and then one day earlier and it all goes astray:
SELECT
TIMESTAMPDIFF( 2, CHAR(TIMESTAMP('2023-12-21-00.00.01') -
TIMESTAMP('2023-10-22-00.00.01'))) AS TSDIFF
, DAYS( TIMESTAMP('2023-12-21-00.00.01')) -
DAYS( TIMESTAMP('2023-10-22-00.00.01')) AS DAYS
FROM SYSIBM.SYSDUMMY1 ;
---------+---------+---------+---------+---------+---------+---------
TSDIFF DAYS
---------+---------+---------+---------+---------+---------+---------
5184000 60
DSNE610I NUMBER OF ROWS DISPLAYED IS 1
SELECT
TIMESTAMPDIFF( 2, CHAR(TIMESTAMP('2023-12-21-00.00.01') -
TIMESTAMP('2023-10-21-00.00.01'))) AS TSDIFF
, DAYS( TIMESTAMP('2023-12-21-00.00.01')) -
DAYS( TIMESTAMP('2023-10-21-00.00.01')) AS DAYS
FROM SYSIBM.SYSDUMMY1 ;
---------+---------+---------+---------+---------+---------+---------
TSDIFF DAYS
---------+---------+---------+---------+---------+---------+---------
5184000 61
DSNE610I NUMBER OF ROWS DISPLAYED IS 1
As you can easily see, the day has changed by one but the TSDIFF has not…Not good! The problem is naturally caused by going over some internal threshold. If you do not care about accuracy, it is fine.
I Do!
So, what I have done is write my own “timestampdiff” in SQL:
SELECT
MIDNIGHT_SECONDS(TIMESTAMP('2023-12-21-00.00.01')) -
MIDNIGHT_SECONDS(TIMESTAMP('2023-10-22-00.00.01'))
+ ( 86400 * (DAYS(TIMESTAMP('2023-12-21-00.00.01')) -
DAYS(TIMESTAMP('2023-10-22-00.00.01')))) AS DIFF
,TIMESTAMPDIFF( 2, CHAR(TIMESTAMP('2023-12-21-00.00.01') -
TIMESTAMP('2023-10-22-00.00.01'))) AS TSDIFF
, DAYS( TIMESTAMP('2023-12-21-00.00.01')) -
DAYS( TIMESTAMP('2023-10-22-00.00.01')) AS DAYS
FROM SYSIBM.SYSDUMMY1 ;
---------+---------+---------+---------+---------+---------+---------
DIFF TSDIFF DAYS
---------+---------+---------+---------+---------+---------+---------
5184000 5184000 60
DSNE610I NUMBER OF ROWS DISPLAYED IS 1
DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 100
---------+---------+---------+---------+---------+---------+---------
SELECT
MIDNIGHT_SECONDS(TIMESTAMP('2023-12-21-00.00.01')) -
MIDNIGHT_SECONDS(TIMESTAMP('2023-10-21-00.00.01'))
+ ( 86400 * (DAYS(TIMESTAMP('2023-12-21-00.00.01')) -
DAYS(TIMESTAMP('2023-10-21-00.00.01')))) AS DIFF
,TIMESTAMPDIFF( 2, CHAR(TIMESTAMP('2023-12-21-00.00.01') -
TIMESTAMP('2023-10-21-00.00.01'))) AS TSDIFF
, DAYS( TIMESTAMP('2023-12-21-00.00.01')) -
DAYS( TIMESTAMP('2023-10-21-00.00.01')) AS DAYS
FROM SYSIBM.SYSDUMMY1 ;
---------+---------+---------+---------+---------+---------+---------
DIFF TSDIFF DAYS
---------+---------+---------+---------+---------+---------+---------
5270400 5184000 61
DSNE610I NUMBER OF ROWS DISPLAYED IS 1
DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 100
---------+---------+---------+---------+---------+---------+---------
SELECT
MIDNIGHT_SECONDS(TIMESTAMP('2023-12-21-00.00.01')) -
MIDNIGHT_SECONDS(TIMESTAMP('2023-10-20-00.00.01'))
+ ( 86400 * (DAYS(TIMESTAMP('2023-12-21-00.00.01')) -
DAYS(TIMESTAMP('2023-10-20-00.00.01')))) AS DIFF
,TIMESTAMPDIFF( 2, CHAR(TIMESTAMP('2023-12-21-00.00.01') -
TIMESTAMP('2023-10-20-00.00.01'))) AS TSDIFF
, DAYS( TIMESTAMP('2023-12-21-00.00.01')) -
DAYS( TIMESTAMP('2023-10-20-00.00.01')) AS DAYS
FROM SYSIBM.SYSDUMMY1 ;
---------+---------+---------+---------+---------+---------+
DIFF TSDIFF DAYS
---------+---------+---------+---------+---------+---------+
5356800 5270400 62
DSNE610I NUMBER OF ROWS DISPLAYED IS 1
It all looks a lot better and actually returns the correct number of seconds between two timestamps!
I use the MIDNIGHT_SECONDS BiF (First appeared in DB2 V6.1) that returns the number of seconds from midnight up to the given timestamp. I then simply subtract the “to ts” value from the “from ts” value and then use the DAYS BiF again subtracting from each other to get the days difference multiplying by 86400 as seconds/day. There is no need to subtract an extra day as, if that was required, it is automatically handled by the MIDNIGHT_SECONDS subtraction. Then these two results are simply added together.
Code Review Time?
I have re-reviewed all my code to make sure that any use of TIMESTAMPDIFF can accept “approximate” answers and in all other cases replaced it with the above code.
I might even open an Aha! Idea about getting this as a BiF – it is not that complex and is “better” than the best guess system we have now. In fact, I have – DB24ZOS-I-1599 – please vote if you think it would be great to get this as a simple BiF!
Db2 Does Not Stand Alone Here!
We are also not alone in this problem! Oracle, MySQL and JAVA all have the same “approximation” routines. I did a Google search for a web-based timestamp calculator and it made exactly the same mistakes. I guess that there is a “fast algorithm” out there that does the best guess quickly…but sadly not accurately!
This problem is right up there with Daylight Saving Time and the grief that causes! See my earlier blog.
You pick your frame of reference and you pays your money, as they say!
Which way should we all be going these days? The good old precompiler, since the beginning of time, or the modern sleek coprocessor? This month, I will show you what they both do, what they do the same, what they do differently, and the pros and cons of both!
COBOL For All!
Yep, this newsletter is *just* about COBOL. Sorry if you use JAVA, Ruby, Python, or CosyPinkTeabags I stick with a language that works on computers so big you cannot lift ‘em!
In the Beginning…
Many, many moons ago, the great precompiler was launched. The problem was that Structured Query Language (SQL) is not COBOL in any way shape or form, but companies needed a way to integrate SQL code into COBOL code. The mainframe world had had this problem before with CICS, where the elegant solution was a CICS translator that ran through the code, removed all the special CICS calls, and replaced them with correctly formed COBOL calls. All done under the covers so that the application programmer did not have to know, or do, anything. CICS also now supports the integrated CICS translator by the way.
SQL was More Complicated
Naturally, the abilities in SQL caused some headaches… The syntax checking required the use of TABLE DECLARES (Still optional to this day, which I find astonishing!) To generate executable code the system had to do two things:
Replace the EXEC SQL with comments and then calls to Assembler routines with parameters that listed out the SQL statement to be executed and all of the host variables involved. It also created a CONTOKEN or Consistency token that Db2 uses to check that any given load module “fits” to the given Package (DBRM) at run time.
Output a DBRM, also with the CONTOKEN within it, so that then the PACKAGE/PLAN could be bound into an executable object. Every statement in the package matched the COBOL assembler calls one to one. At execution time, if the CONTOKEN in the package did not match the CONTOKEN in the load module, you would get a nasty error, typically an SQLCODE -805 with one of five sub-types, as something is wrong somewhere!
The Problem?
At the point where the precompiler was run, *no* COBOL had been compiled so any use of COPY books caused syntax errors – here the EXEC SQL INCLUDE jumped in to help *but* for, some unknown reason, they did not implement a REPLACING syntax like COPY has… This meant that the INCLUDEd code was not 100% the same as your “normal” COPY book – Very annoying!
Coprocess This!
This situation caused problems, and after a few years IBM launched the coprocessor which is basically the IBM COBOL compiler with the precompiler bolted within. This gave two immediate benefits:
Simpler JCL (No precompiler step anymore!)
Simpler COBOL copy book management as the COPY syntax worked fine!
So Why are We Not *All* Using the Coprocessor Today?
Well, as always, the devil is in the detail. The one major stopper I have seen is Db2 columns defined as “FOR BIT DATA”. Now, in the normal COBOL world, this just means “no code page conversion please.” The data is quite probably hexadecimal and will be completely mangled if it gets a code page conversion! What you actually get depends on what you are doing but it is quite easy to get an SQLCODE -333.
Unicode – EBCDIC – ASCII
The triumvirate of pain! If I had a dollar for every file transfer I have received that was originally EBCDIC and got ASCII transferred… but I digress!
There is a Fix!
There are two solutions here:
Use a DECLARE VARIABLE in the code to “inform” the Compiler *not* to do a code page conversion when this COBOL host variable is being processed. This is naturally more work for the programmer and “dangerous” too, as it is another “point of failure” that never existed before! This scares people – we all hate change after all.
Use NOSQLCCSID in the COBOL coprocessor parameters. This is recommended as the easiest way to stay plug compatible with the precompiler. Naturally, at some point, it will be time to bite the bullet and do the code change required!
The DECLARE you might need looks like this:
exec sql
declare :PACKAGE-CONTOKEN variable for bit data
end-exec
The problem is normally caused by INSERT and UPDATE processing. Just SELECT appears to always work fine in my tests, (I created an EBCDIC table and a UNICODE table and then did multiple Inserts and Selects with hex data). However, your data constellation might well be different from mine – Always test first!
Bottom Line
If you are not using FOR BIT DATA you have no problem!
Here’s a little SQL to show you where you have any columns with FOR BIT DATA in your system:
SELECT SUBSTR(STRIP(TBCREATOR) CONCAT '.' CONCAT STRIP(TBNAME)
, 1 , 32) AS TABLE_NAME
, NAME AS COL_NAME
FROM SYSIBM.SYSCOLUMNS
WHERE FOREIGNKEY = 'B'
ORDER BY 1 , 2
FOR FETCH ONLY
WITH UR
;
JCL Changes Required
To get the Coprocessor up and running I just added these two lines into my SYSOPTF for COBOL 6.3:
All in all, I think if you are still using the precompiler you should take some time to migrate over to the coprocessor as it makes the modules much smaller and, by default, faster!
Faster? I Hear you Shout
Well, what the coprocessor also does, is completely remove all SQL based working storage and, most importantly, the PERFORM on the 1st call of the SQL-INITIAL section. Now the precompiler is clever but it is not Einstein! When the very first SQL gets called, this section is performed which defines in memory *all* the SQL in the program. So, let’s say you have a program with 1,000 SQLs. You are only using one of them, but for that one call all 1,000 working storage areas will be initialized through DSNHADDR and DSNHADD2 calls using the PLIST blocks. It is fast I know, but it is also just overhead!
Another Bonus!
Plus, if your COBOL is passing host variables through linkage section usage and the address changes between calls then you *must* currently reset the SQL-INIT-FLAG to zero *every* time… With the coprocessor you do not have to do that anymore – Another win!
Just the Facts Ma’am
In one of my test programs the precompiler generated:
1674 lines of working storage
232 lines of SQL-INITIAL code
For every EXEC SQL (31 in total) that was commented out a
PERFORM SQL-INITIAL UNTIL SQL-INIT-DONE
CALL 'DSNHLI2' USING SQL-PLIST11
END-CALL
Block was written.
The coprocessor generated nothing! and the executable load module was 8% smaller!
Pros and Cons
Pros of precompiler are: No need to DECLARE for bit data columns and no JCL change.
Cons of precompiler are: No real COPY book support, larger code and bigger module size.
Pros of coprocessor are: No reset of SQL-INIT-FLAG, Perfect COPY book support, no generated code, smaller module size, faster run time execution and load.
Cons of coprocessor are: JCL change required and possible DECLARE VARIABLEs needed depending on usage.
What are your experiences with the precompiler and/or the coprocessor?
This month, I must thank one of my readers who simply asked, “Roy, can you do a newsletter about the Shared Communications Area (SCA) for me please?” Naturally, I replied (after getting two beers from him of course!) So now I wish to delve into the inner workings of the Coupling Facility (CF) and the SCA…
Warning: Scary Stuff Ahead!
In a non-datasharing world, a -DISPLAY GROUP shows this sort of output:
DSN7100I -DD10 DSN7GCMD
*** BEGIN DISPLAY OF GROUP(........) CATALOG LEVEL(V13R1M504)
CURRENT FUNCTION LEVEL(V13R1M504)
HIGHEST ACTIVATED FUNCTION LEVEL(V13R1M504)
HIGHEST POSSIBLE FUNCTION LEVEL(V13R1M504)
PROTOCOL LEVEL(2)
GROUP ATTACH NAME(....)
---------------------------------------------------------------------
DB2 SUB DB2 SYSTEM IRLM
MEMBER ID SYS CMDPREF STATUS LVL NAME SUBSYS IRLMPROC
-------- --- ---- -------- -------- ------ -------- ---- --------
........ 0 DD10 -DD10 ACTIVE 131504 S0W1 IDD1 DD10IRLM
---------------------------------------------------------------------
SPT01 INLINE LENGTH: 32138
*** END DISPLAY OF GROUP(........)
DSN9022I -DD10 DSN7GCMD 'DISPLAY GROUP ' NORMAL COMPLETION
If that is what you see in your production system, dear reader, then this newsletter is, sadly, not for you!
Hopefully your output actually looks like my little test system:
DSN7100I -SD10 DSN7GCMD
*** BEGIN DISPLAY OF GROUP(GSD10C11) CATALOG LEVEL(V13R1M504)
CURRENT FUNCTION LEVEL(V13R1M504)
HIGHEST ACTIVATED FUNCTION LEVEL(V13R1M504)
HIGHEST POSSIBLE FUNCTION LEVEL(V13R1M504)
PROTOCOL LEVEL(2)
GROUP ATTACH NAME(SD1 )
---------------------------------------------------------------------
DB2 SUB DB2 SYSTEM IRLM
MEMBER ID SYS CMDPREF STATUS LVL NAME SUBSYS IRLMPROC
-------- --- ---- -------- -------- ------ -------- ---- --------
MEMSD10 1 SD10 -SD10 ACTIVE 131504 S0W1 JD10 SD10IRLM
MEMSD11 2 SD11 -SD11 ACTIVE 131504 S0W1 JD11 SD11IRLM
---------------------------------------------------------------------
SCA STRUCTURE SIZE: 16384 KB, STATUS= AC, SCA IN USE: 3 %
LOCK1 STRUCTURE SIZE: 16384 KB
NUMBER LOCK ENTRIES: 4194304
NUMBER LIST ENTRIES: 16354, LIST ENTRIES IN USE: 81
SPT01 INLINE LENGTH: 32138
*** END DISPLAY OF GROUP(GSD10C11)
DSN9022I -SD10 DSN7GCMD 'DISPLAY GROUP ' NORMAL COMPLETION
The interesting stuff is from the “SCA STRUCTURE SIZE:” line down to the “NUMBER LIST ENTRIES:” line.
Off We Go!
To understand what an SCA is, we need to backtrack a second and first discuss what a CF is?
What is Inside?
The Coupling Facility is de facto *the* central part of data sharing, it contains three objects:
A lock structure called LOCK1, where all the table locks using hashes live, and Record Lock Elements (RLE),
A list structure that is actually the SCA, which contains a bunch of stuff I will go into later,
The Group Buffer pools. Technically, you can run without these but then why are you data sharing if you are not sharing data?
Lock Structure Details
It is called LOCK1 and the system lock manager (SLM) uses the lock structure to control shared Db2 resources like tablespaces and pages and can enable concurrent access to these. It is split internally into two parts: The first part is the Lock Table Entry (LTE), and the second part is a list of update locks normally actually called the Record List Entry (RLE). The default is a 50:50 split of memory. The size of this structure must be big enough to avoid hash contention, which can be a major performance problem. Do not forget that the IRLM reserves 10% of the RLEs for “must complete” processes so you never actually get to use them all!
List Structure Details
This is really the SCA and it contains Member names, BSDS names, Data Base Exception Table (DBET) statuses and recovery information. Typically, at installation time, you pick a number for the INITSIZE (first allocated size of the SCA) from a list of 16 MB , 32 MB, 64 MB or 128 MB. Each of these INITSIZEs then has a SIZE which is typically twice the INITSIZE size as a maximum limit.
Baboom!
IBM write quite happily “Running out of SCA space can cause Db2 to fail” – I can change that to “does” not “can”!
Double Trouble?
The LOCK1 and the SCA do *not* have to be duplexed but it is very highly recommended to do so, otherwise, you have a single point of failure which defeats the whole point of going data sharing, really.
Death by DBET
The DBET data is, strangely enough, the thing that can easily kill ya!
How So?
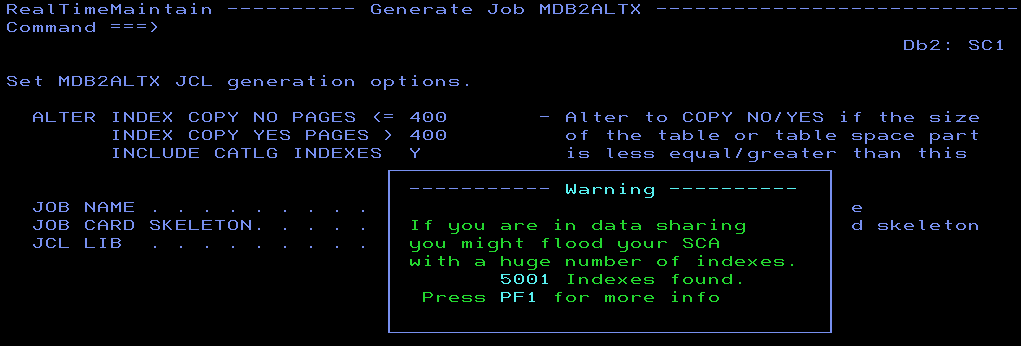
Imagine you have the brilliant idea of using COPY YES indexes as you have tested a few and seen that RECOVER INDEX is quicker, better, faster than REBUILD or DROP/CREATE for the critical indexes at your shop.
What Happened Next?
So how do you enable COPY YES at the index level? Just a simple ALTER INDEX xxx.yyy COPY YES is all it takes. But *what*, dear friends, does this ALTER do under the covers? It sets the INDEX to ICOPY status – “Not too bad”, you say as the index is fully available, “just wait until the next COPY and that status is then cleared” – But wait, that is a DBET status! It creates a DBET entry in your SCA… What if you alter 15,000 Indexes to all be COPY YES? Yep – Kiss goodbye to your Db2 sub-system!
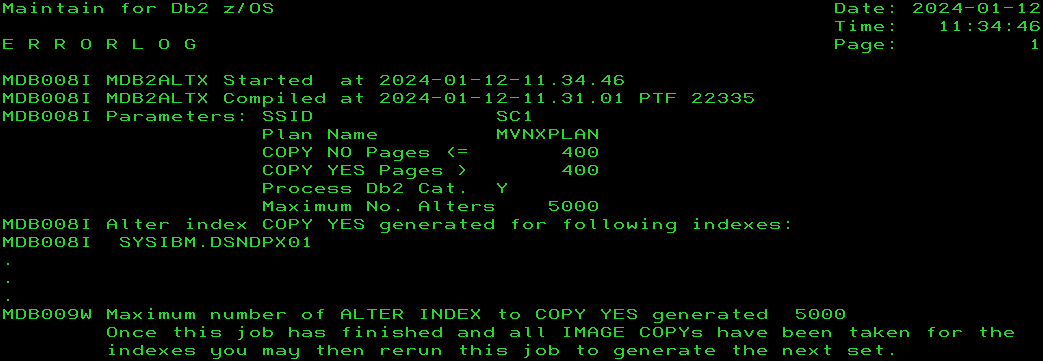
Suicide Protection
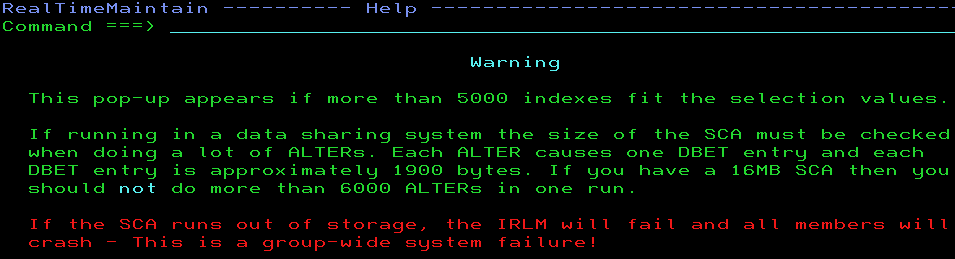
Some software out there (RealTimeDBAExpert from SEGUS for example!) actually warns you about this and recommends you do this sort of thing in chunks. First the ALTER, then the COPY, one hundred blocks at a time and then the next batch etc.
and then if you do press PF1:
And even then, we have an emergency stop built-in that you can still override but then you must *know* the possible risk involved:
On the other hand, some software is like using SDSF DA when you put a P for “print” by your userid!
Now you know what *not* to do!
Automagic?
Use of the ALLOWAUTOALT(YES) has been discussed for years… on the one hand it automagically adds storage if you are running out, which is a good thing, *but* it also allows other competing systems to decrease storage which can then lead to you running out of storage and losing this Db2 sub-system… nasty, nasty!
Operator command time!
/f <yourirlm>,STATUS,STOR
Gives me:
DXR100I JD11002 STOR STATS
PC: YES LTEW: 2 LTE: 4M RLE: 16354 RLEUSE: 18
BB PVT: 1266M AB PVT (MEMLIMIT): 2160M
CSA USE: ACNT: 0K AHWM: 0K CUR: 2541K HWM: 6122K
ABOVE 16M: 64 2541K BELOW 16M: 0 0K
AB CUR: 0K AB HWM: 0K
PVT USE: BB CUR: 5684K AB CUR: 5M
BB HWM: 18M AB HWM: 5M
CLASS TYPE SEGS MEM TYPE SEGS MEM TYPE SEGS MEM
ACCNT T-1 2 4M T-2 1 1M T-3 2 8K
PROC WRK 14 70K SRB 5 5K OTH 4 4K
MISC VAR 41 7549K N-V 22 565K FIX 1 24K
This maps pretty nicely to the – DISPLAY GROUP I just did again:
*** BEGIN DISPLAY OF GROUP(GSD10C11) CATALOG LEVEL(V13R1M504)
CURRENT FUNCTION LEVEL(V13R1M504)
HIGHEST ACTIVATED FUNCTION LEVEL(V13R1M504)
HIGHEST POSSIBLE FUNCTION LEVEL(V13R1M504)
PROTOCOL LEVEL(2)
GROUP ATTACH NAME(SD1 )
---------------------------------------------------------------------
DB2 SUB DB2 SYSTEM IRLM
MEMBER ID SYS CMDPREF STATUS LVL NAME SUBSYS IRLMPROC
-------- --- ---- -------- -------- ------ -------- ---- --------
MEMSD10 1 SD10 -SD10 ACTIVE 131504 S0W1 JD10 SD10IRLM
MEMSD11 2 SD11 -SD11 ACTIVE 131504 S0W1 JD11 SD11IRLM
---------------------------------------------------------------------
SCA STRUCTURE SIZE: 16384 KB, STATUS= AC, SCA IN USE: 3 %
LOCK1 STRUCTURE SIZE: 16384 KB
NUMBER LOCK ENTRIES: 4194304
NUMBER LIST ENTRIES: 16354, LIST ENTRIES IN USE: 18
SPT01 INLINE LENGTH: 32138
*** END DISPLAY OF GROUP(GSD10C11)
Looking at this line in the Modify output:
PC: YES LTEW: 2 LTE: 4M RLE: 16354 RLEUSE: 18
I only have two members so my LTEW (LTE Width) is two bytes, LTE is 4M which is my NUMBER LOCK ENTRIES: 4194304 , RLE is 16354 which is my NUMBER LIST ENTRIES: 16354 and RLEUSE is 18 which is my LIST ENTRIES IN USE: 18. A perfect match – if only they had agreed on a naming convention! ! !
You can also see that my SCA STATUS is AC for ACTIVE and the SCA IN USE is a measly 3%, so no worries for me today!
Finally, you can see that we have 50:50 split as the SCA and the LOCK1 are the same size: 16 MB.
One more line of interest:
BB PVT: 1266M AB PVT (MEMLIMIT): 2160M
Here you can see the calculated MEMLIMIT for the IRLM, which for my test system is very low, but you should check that the number is good for your site as the range is now much bigger!
Panic Time?
I would start to get seriously sweaty if the SCA IN USE ever got near 70%.
And?
I would not use ALLOWAUTOALT(YES) and allocate 256MB or, if forced, I would go with INITSIZE 128 MB and SIZE 256 MB and then ALLOWAUTOALT(YES).
Lock it Down!
The Max Storage for locks is between 2,048 MB and 16,384 PB with a default of 2,160 MB that I have in the PVT (MEMLIMIT) output above.
Locks per table(space) (NUMLKTS) is 0 to 104,857,600 with a default of 2,000 in Db2 12 and 5,000 in Db2 13. If this number is exceeded then lock escalation takes place unless it is zero in which case there is no lock escalation. As IBM nicely put it “Do not set the value to 0, because it can cause the IRLM to experience storage shortages”.
Locks per user (NUMLKUS) is also from 0 to 104,857,600 with a default of 10,000 in Db2 12 and 20,000 in Db2 13. 0 means no limit. IBM do not recommend 0 or a large number here unless it is really required to run an application. Db2 assumes that each lock is approximately 540 bytes of memory. Here you can also drain your IRLM until it runs out of ACCOUNT T-1 storage space:
DXR175E xxxxxxxx IRLM IS UNABLE TO OBTAIN STORAGE – PVT
This is not a message you ever want to see on the master console! Just do the math on your locks and your memory size!
The Bachelor Problem – Fear of Commitment
You must get the developers to COMMIT or not use row-level locking everywhere.
SCA DBET Calculation
The lock size for each DBET entry is approximately 1,864 bytes from my tests in Db2 12 FL 510. How did I determine that, you ask?
What I did, was multiple ALTER INDEX aaa.bbb COPY YES SQLs until the “SCA in use” percentage changed from 4% to 5%, and then I kept doing ALTERs and DISPLAYs until the percentage changed from 5% to 6%. It took me exactly 90 ALTERs and with an SCA size of 16,384KB, that gives me a size of around 1,864 bytes per DBET entry. Use this as a Rule Of Thumb for your DBET inducing ALTERs! It gives me a hard limit of about 6,000 Alters.
I hope you found this little discourse into the world of the Coupling Facility and SCA useful!
This month is all about going parallel! In the Db2 world, we have had the ability to run SQLs using parallel processing for decades. It started off a bit wobbly and most people didn’t use it, or even like it, but these days it is extremely useful for certain cases.
Sort Yourself Out
Sort is very important here. If you can do a parallel sort with only one extra parallel task it will halve your elapsed time… if you can add more tasks it takes even less elapsed. Naturally, you do not save on CPU here, in fact it will probably “cost” more, but you are trading CPU for elapsed time.
Ground Rules
IBM states in the documentation that parallel processing is “Only for partitioned objects” but then they mention that even non-partitioned objects can benefit, as the access to the non-clustering index and the data can be done in parallel… which is not helpful if you only have clustering index access, of course!
Bells and Whistles!
There are quite a few things to adjust and play with on the road to parallel processing!
No Way!
If you declare your cursor as WITH HOLD and with isolation level RR or RS then there is *no* CPU parallelism allowed at all but you can still get parallel sorts.
ZPARM Time
First up is CDSSRDEF (CURRENT DEGREE) where the IBM recommendation must be read:
CURRENT DEGREE field (CDSSRDEF subsystem parameter)
The CDSSRDEF subsystem parameter determines the default value that is to be used for the CURRENT DEGREE special register. The default value is used when a degree is not explicitly set in the SQL statement SET CURRENT DEGREE.
Acceptable values: 1, ANY
Default: 1
Update: option 30 on panel DSNTIPB
DSNZPxxx: DSN6SPRM CDSSRDEF
1 Specifies that when a query is dynamically prepared, the execution of that query will not use parallelism. If this value is specified, Db2 does not use any optimization hints for parallelism.
ANY Specifies that when a query is dynamically prepared, the execution of that query can involve parallelism.
Recommendation: In almost all situations, accept the default value of 1. You should use parallelism selectively where it provides value, rather than globally. Although parallelism can provide a substantial reduction in elapsed time for some queries with only a modest overhead in processing time, parallelism does not always provide the intended benefit. For some queries, and in many other situations, query parallelism does not provide an improvement, or it uses too many resources. If you are using nearly all of your CPU, I/O, or storage resources, parallelism is more likely to cause degradation of performance. Use parallelism only where it is most likely to provide benefits.
The ZPARM INDEX_IO_PARALLELISM should get an honorable mention here as it was there right up until Db2 11 and it is, in fact, still within the Db2 12 and 13 indexes at the end of the installation guide pdf, but it has thrown off its mortal coil…
INDEX_IO_PARALLELISM
Specifies whether I/O parallelism is enabled for index insertion.
Acceptable values: YES, NO
Default: YES
DSNZPxxx: DSN6SPRM INDEX_IO_PARALLELISM
Security parameter: No
YES I/O parallelism is enabled for index processing. I/O parallelism allows concurrent insert operations on multiple indexes and can reduce I/O wait time when many indexes are defined in a table.
NO I/O parallelism is disabled for index processing.
Naturally, YES is what it should be set to!
To round out the dearly departed, there was also this one:
PARALLELISM EFFICIENCY field (PARA_EFF subsystem parameter)
Controls the efficiency that DB2 assumes for parallelism when DB2 chooses an access path. Valid values are integers 0 – 100. The integer represents a percentage efficiency.
It came in Db2 9 with PM16020 and started life with a default value of 100 before getting a default change to 50 in Db2 10. It got deprecated in Db2 12 and was removed in Db2 13.
Then PARAMDEG with a handy Top Tip:
MAX DEGREE field (PARAMDEG subsystem parameter)
The PARAMDEG subsystem parameter specifies the maximum degree of parallelism for a parallel group. When you specify a non-zero value for this parameter, you limit the degree of parallelism so that Db2 cannot create too many parallel tasks that use virtual storage.
Acceptable values: 0 – 254
Default: 0
Update: option 30 on panel DSNTIPB
DSNZPxxx: DSN6SPRM PARAMDEG
0 Specifies no limit to the maximum degree of parallelism that Db2 chooses based on the cost estimate for the query and the system configuration, in particular the number of processors online. Db2 counts both general purpose and zIIP processors equally, and applies further adjustment to determine the degree to use.
1 – 254 Specifies the maximum degree of parallelism that Db2 uses. When optimization hints for parallelism are used, the value of the PARAMDEG subsystem parameter does not limit the degree of parallelism at bind time. However, the value of the PARAMDEG subsystem parameter is enforced at execution time. So, if the value of the PARAMDEG subsystem parameter is lower than the degree of parallelism that is specified at bind time, the degree of parallelism is reduced at execution time.
Tip: For systems with more than two zIIP processors configured, use the number of zIIP processors as the starting value, and then adjust as needed for your response time requirements.
Basically, set this value to be one or two times the number of online available CPUs but take into account the ZiiPs.
Then its new DPSI baby brother:
MAX DEGREE FOR DPSI (PARAMDEG_DPSI subsystem parameter)
The PARAMDEG_DPSI subsystem parameter specifies the maximum degree of parallelism that you can specify for a parallel group in which a data partitioned secondary index (DPSI) is used to drive parallelism.
A DPSI is a non-partitioning index that is physically partitioned according to the partitioning scheme of the table. When you specify a value of greater than 0 for this parameter, you limit the degree of parallelism for DPSIs so that Db2 does not create too many parallel tasks that use virtual storage.
Acceptable values: 0-254, DISABLE
Default: 0
Update: option 30 on panel DSNTIPB
DSNZPxxx: DSN6SPRM PARAMDEG_DPSI
Data sharing scope: All members use the same setting
0 Specifies that Db2 uses the value that is specified for the PARAMDEG subsystem parameter, instead of PARAMDEG_DPSI, to control the degree of parallelism when DPSI is used to drive parallelism. This is the default value for the field.
1 Specifies that Db2 creates multiple child tasks but works on one task at a time when DPSI is used to drive parallelism.
2-254 Specifies that Db2 creates multiple child tasks and works concurrently on the tasks that are specified. The number of specified tasks may be larger or smaller than the number of tasks as specified in PARAMDEG. When PARAMDEG is set to 1, the rest of the query does not have any parallelism.
DISABLE Specifies that Db2 does not use DPSI to drive parallelism. Parallelism might still occur for the query if PARAMDEG is greater than 1.
This is for fine-tuning the DPSI use case. Remember, you can have 4096 partitions and so it could well be that a query goes crazy if it sees the ability to go massively parallel. Here you can limit, or even inhibit, that from happening. Only use if you have been bitten by a rogue SQL!
Then we get to Utility parallel processing which is not for all Utilities – but REORG TABLESPACE and COPY are there!
MAX UTILS PARALLELISM field (PARAMDEG_UTIL subsystem parameter)
The PARAMDEG_UTIL subsystem parameter specifies the maximum number of parallel subtasks for some utilities.
PARAMDEG_UTIL affects the following utilities:
• REORG TABLESPACE
• REBUILD INDEX
• CHECK INDEX
• UNLOAD
• LOAD
• COPY
• RECOVER
Acceptable values: 0 – 32767
Default: 99
Update: option 34 on panel DSNTIPB
DSNZPxxx: DSN6SPRM PARAMDEG_UTIL
0 No additional constraint is placed on the maximum degree of parallelism in a utility.
1 – 32767 Specifies the maximum number of parallel subtasks for all affected utilities.
Interesting default huh? In Db2 11 it was actually zero!
LOAD must get a special mention here, as back in Db2 11 it got a new keyword PARALLEL ( nnn ) which enabled parallel loading from a *single* input file (Initially not for PBGs but then that was allowed in Db2 12). This little chestnut has often been forgotten.
Further into the guts of REORG is this little one:
REORG LIST PROCESSING field (REORG_LIST_PROCESSING subsystem parameter)
The REORG_LIST_PROCESSING subsystem parameter specifies the default setting for the PARALLEL option of the Db2 REORG TABLESPACE utility.
Acceptable values: PARALLEL, SERIAL
Default: PARALLEL
Update: option 37 on panel DSNTIPB
DSNZPxxx: DSN6SPRM REORG_LIST_PROCESSING
PARALLEL The default value PARALLEL specifies that the REORG TABLESPACE utility is to use a default PARALLEL YES option when the PARALLEL keyword is not specified in the utility control statement. The PARALLEL YES option specifies that the REORG TABLESPACE utility is to process all partitions that are specified in the input LISTDEF statement in a single execution of the utility.
SERIAL Specifies that the REORG TABLESPACE utility is to use a default PARALLEL NO option when the PARALLEL keyword is not specified in the utility control statement. The PARALLEL NO option specifies that each partition that is specified in the input LISTDEF statement is to be processed in a separate execution of the utility.
I would also happily stick with the default unless you have experienced serious problems with VTS or some such.
Don’t Forget the Bufferpool, Stupid!
BUFFERPOOLs play a major role. The setting of VPSEQT (Virtual bufferpool sequential steal threshold) and VPPSEQT (Virtual bufferpool parallel sequential threshold) might well both have to be raised. Remember that the VPPSEQT is a percentage of the VPSEQT available pages. The bufferpool size itself might well have to be raised (VPSIZE) if you do not see an improvement in the degree of parallelism.
All Ready?
So, you have set, checked, reviewed, changed the ZPARMS and are ready to go?
Where’s the ON Switch?
For Static SQL just bind or rebind with DEGREE(ANY), for dynamic SQL issue a
SET CURRENT DEGREE = ‘ANY’ ;
CDSSRDEF Zparm has the default for this parameter.
If you bind with isolation level CS, then also try and make sure you use CURRENTDATA(NO) as well. This helps performance anyway and also aids Db2 in working with ambiguous cursors. Explicit read-only is always better!
For sorts, where the big elapsed time gains come from, make sure you have sufficiently sized work files allocated! Here, even the WITH HOLD and isolation RR or RS can benefit.
Gotchas?
Always at least one problem isn’t there? If you do DEGREE(ANY) you can expect the EDMPOOL usage to go up between 50% and 70% due to run-time structures. Check your SYSPACKAGE AVGSIZE before and after the BIND/REBIND if you are worried. Always monitor this pool and make sure it is correctly sized for your workload!
Naturally, the CPU might well go up but you should see a good drop in elapsed times and, as far as sort is concerned, you might actually manage a successful parallel sort in a normally constrained sub-system!
Where’s the OFF Switch?
For Static SQL just bind or rebind with DEGREE(1), for dynamic SQL issue a
SET CURRENT DEGREE = ‘1’;
This is also the default value but what if someone changed your default?
If you shrink the VPPSEQT to 0 that will disable all parallel access for objects in that bufferpool.
Insert rows in the resource limit tables – Not recommended as this is a lot of work!
Are You Running in Parallel then? EXPLAIN is Your Friend!
There are a few “access patterns” that allow CP parallelism and they are all documented in the Managing Performance book – “Checklist of query restrictions for query CP parallelism” table.
How do You Check?
The columns of interest in the PLAN_TABLE are the ACCESS_DEGREE and JOIN_DEGREE. If either of these two is not NULL then you are using, or hoping to use, parallel processing! The moment you have more than one table then four other columns become interesting: ACCESS_PGROUP_ID, JOIN_PGROUP_ID, SORTN_PGROUP_ID and SORTC_PGROUP_ID. PGROUP is short for PARALLEL GROUP and for a given PLANNO step they all have the same number. Finally, the PARALLELISM_MODE reflects which type you are using which, these days, can *only* be ‘C’ for Query CP parallelism (Came in DB2 V4). It used to also have the values ‘I’ for parallel I/O operations (Came in DB2 V3) and ‘X’ for Sysplex query parallelism (Came in DB2 V5) but they were deprecated in Db2 9 and are now both dead and buried!
Which SQLs are Best for Parallel Processing?
SQLs that are I/O intensive and scan lots of pages while returning just a few rows, SQLs that have lots of aggregate functions, and naturally SQLs that require Sort – all of these are good candidates.
Trial it DUMMY!
Best thing to do is a trial rebind to a dummy collection of all your SQL in a sandbox system with production statistics copied over and with parallel processing enabled (Do not forget the bufferpools!). This will then quickly reveal which queries could indeed benefit from going parallel and enable you to activate it only at the package/SQL level that you require in production.
Apply and Test
Once you have your candidate list, and I hope it is not that long, you can simply enable it all in production and do a live run through and review. First with EXPLAIN and then really live.
Remember that it is not good for *all* SQLs but it can really help when it hits the spot!
My Favorite Table Ever!
Db2 11 introduced an automatic five level control system for parallel queries:
Level 1 OK: Query runs with planned parallel degree
Level 2 Mild warning: Reduce parallel degree by ¼
Level 3 Moderate warning: Reduce parallel degree by ½ or to degree 2
Level 4 Severe warning: Reduce to sequential run
Level 5 Melt down: Reduce to sequential run
Level 5 is sub-optimal!
The original table is here: (Do a search for “Melt”)
For static SQL, just bind/rebind with DEGREE(1) to switch off or DEGREE(ANY) to switch on.
For dynamic SQL, if you cannot add the SET CURRENT DEGREE = ‘ANY’ and RLF tables do not work for you then the only way is to assign the tables in question to their own bufferpools and set the VPPSEQT to a value, or leave at default 50, and for *all* other bufferpools set the VPPSEQT to 0 which switches off parallel processing.
Another way of handling dynamic, but a bit over the top for my taste, is a new data-sharing member where the ZPARM CDSSRDEF is set to ‘ANY’. Then any dynamic work that should be allowed to go parallel is simply routed to just this member.
Whaddya all think?
Going to start testing out parallel processing anytime soon?
I’d love to hear from you!
TTFN
Roy Boxwell
Feedback:
One of my readers mentioned that the primary reason they use parallelism is to increase zIIP offload which offers not just elapsed reduction but also saves the cost of the cpu as well.
Naturally, if you get this, then you are really laughing all the way to the bank!
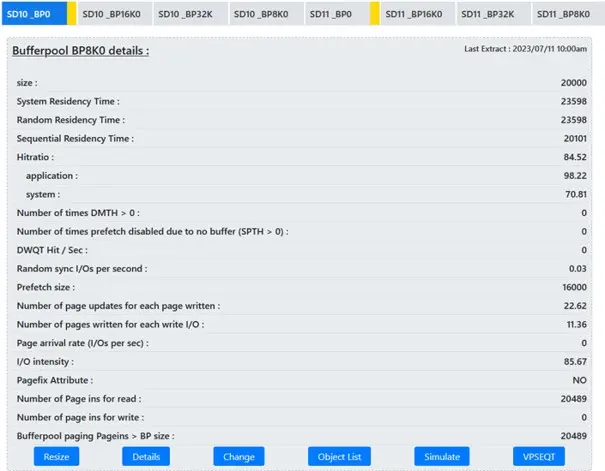
Hi all! This month, I would like to share some things that I have recently learned about Db2 for z/OS buffer pool management and tuning as there was some chatter on Listserv about the sizing of buffer pools.
It all started with some Freeware…
Well actually my freeware! SEG created a BPOOL check freeware program to do a quick analysis of your local and group buffer pools. This freeware you can download here is based upon the rules of our new SQL WorkloadExpert (WLX) Buffer pool Use Case where WLX checks and recommends changes to your buffer pools as well as generating the ALTERs you need.
Readers responded
What we saw, after looking at the responses, was *all* sites have buffer pool problems and are not even aware of them!
Bigger is Better!
Well, actually, no … Dan Luksetich and John Campbell had a conversation a few years ago about the topic of “When is too big too bad?” The basic rub of the matter was this:
“LRU chains (queues, whatever you want to call them) are initially allocated at 4,000 pages. For small pools, the chains are allocated as needed, up to 255 chains. Then once you are over 1,020,000 pages, the chains grow in size. At about 800GB to 1TB the user starts to see CPU go up as management of the longer chains becomes excessive. … In addition, if you have a very large pool, you’ll want to set VDWQT and DWQT very low. I have VDWQT at 0,128 for some large pools and others at 1%.”
One Big Pool Or …
So, if you had decided to get monolithic on your BP definitions, it might well be time to do a quick rethink and spread the load across multiple largish (up to 800 GB) buffer pools.
Do Not Forget the DWQTs!
We should not be forgetting to take care of DWQT and its vertical assistant, the VDWQT, with its two values – Just percentage of the buffer pool or, after a comma, an absolute number of pages going up to 9999. These two values are specifically designed for large buffer pools where 1% just doesn’t hack it as a trigger for deferred write. Imagine our example buffer pool before with 1,020,000 pages – 1% is still a huge 10,200 pages!
Why Do We Have Buffer Pools?
Remember, the point of buffer pools is to stop I/O and so trickling these updates out instead of hammering them out is definitely a good way forward!
Seeing is Believing!
Do a few -DISPLAY BUFFERPOOL(xxx) DETAIL(*) commands (obviously replacing xxx with your buffer pool of choice) and check out the counters in the DSNB421I message. If you also compute how long the buffer pool has been active, or you do two commands separated by a known amount of time ,you can then simply calculate /sec values. If you are getting more than 1 DWT HIT per second then it is time to act. Same is true for VERTICAL DWT HIT but you can afford to get more of these than the DWT HIT ones!
Groups are Good?
You always get a good feeling traveling in a group, and theoretically, it should be the same with GROUP BUFFERPOOLS, as these beasts control the buffer pool usage between members in a data-sharing system. Normally, they are set up and then simply forgotten about! After all, if all is working who cares?
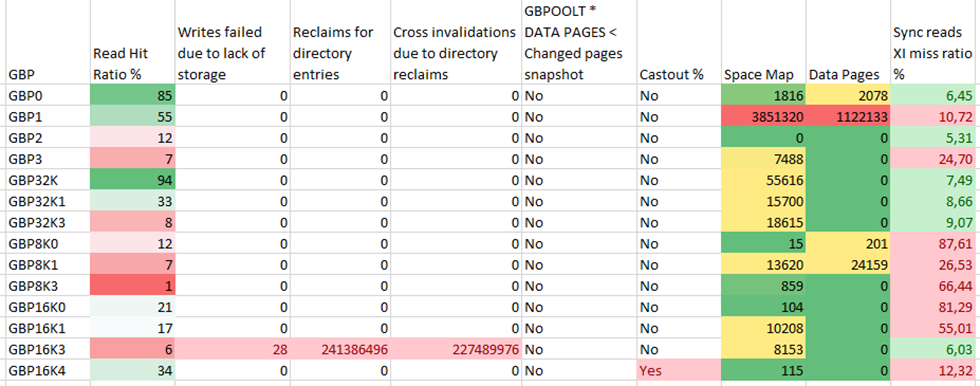
How Does it Look?
Here’s the output of a post processed by me in Excel, -DIS GROUPBUFFERPOOL(*) TYPE(GCONN) GDETAIL(*) MDETAIL(*) command:
Not good!
We all know that the Read Hit Ratio % can basically be ignored at the group level so that’s ok.
But glance down at GBP16K3 – Storage problems, massive reclaims and cross invalidations aplenty. This group buffer pool *must* be examined under the microscope!
The Db2 Guru Says
John Campbell commented:
“It is possible that the reference to updated data across members is very low. But if the miss ratio is elevated across most of the GBPs this not a likely explanation. If check that there no directory entry reclaims causing XIs. These should be tuned away first ie increase INITSIZE and RATIO. Then go after tuning to reduce XI misses by increasing INITSIZE. In both cases rebuild of respective GBP will be required.”
Just the Facts Ma’am
In this case, the first thing is to ratify the RATIO and INITSIZE.
Size of all local BPs for BP16K3 is 40,000 pages
Current directory to data ratio is 10
Allocated size is 65536, so 64 MB
Number of directory entries is 30,771
Number of data pages is 3,076
From this you can derive* that the starting size (INITSIZE) of GB16K3 should be increased to at least 89 MB, which then gives 44,445 Directory entries and 4,445 data pages.
Monitor Monitor Monitor
Once this change has been implemented the GBPs must be monitored to see if RATIO could/should be changed. Then check out that the Writes failed, Reclaims for directory and especially the Cross-Invalidation counters all go down!
A Little Tweak Can Work Wonders!
Buffer pool tuning is not new and will never go away, but you can get very good system-wide improvements with a few well aimed tweaks!
TTFN.
Roy Boxwell
* When I say “derive” what I meant is:
Add up all the Local BPs VPSIZE for each member -> A (directory entries)
Divide this number by the RATIO and round up -> B (data entries required for above directories)
Divide this number by the RATIO and round up -> C (directory entries)
Divide this number by the RATIO and round up -> D (data entries required for above directories)
Iterate until the value is less than RATIO and then use the value -> 1
Add *all* of the numbers A, B, C, D, E … to get total number of directory entries NNNNN
Multiply NNNNN by 430 (size of a directory entry) and then divide by 1048576 rounding up, to get the size of the Directory Entries OOOOO in MB
Divide NNNNN by the RATIO rounding up, to get the total number of Data Entries required, then multiply this by the Bufferpool size in K (4, 8, 16 or 32) and divide by 1024 rounding up to get the size of the Data Entries MMMMM in MB
Add MMMMM and OOOOO to get the recommended GBP starting size in MB.
Aren’t I supposed to be wishing Happy New Year there? Not this month! One of my readers asked me a question about SQLCODEs and it opened up a quite fascinating can of worms!
What is the SQLCODE?
Anyone reading this blog should already know exactly what the SQLCODE is, however, for those of you out there using Google in 2045, the definition is, at least in COBOL:
The third field within the SQLCA is the SQLCODE, which is a four-byte signed integer and it is filled after every SQL call that a program/transaction makes.
All Clear So Far?
So far so good! In the documentation from IBM is this paragraph about how to handle and process SQLCODEs:
SQLCODE
Db2 returns the following codes in SQLCODE:
• If SQLCODE = 0, execution was successful.
• If SQLCODE > 0, execution was successful with a warning.
• If SQLCODE < 0, execution was not successful.
SQLCODE 100 indicates that no data was found.
The meaning of SQLCODEs, other than 0 and 100, varies with the particular product implementing SQL.
Db2 Application Programming and SQL Guide
So, every programmer I have ever talked to checks if the SQLCODE is 0 – Green! Everything is fine, if the SQLCODE is negative – Bad message and ROLLBACK, if the SQLCODE is +100 – End of cursor or not found by direct select/update/delete – normally 100% Ok, everything else issues a warning and is naturally very dependent on the application and business logic!
What’s Wrong With This Picture?
Well, sometimes zero is not really zero… I kid you not, dear readers! The sharp-eyed amongst you, will have noticed the last bytes of the SQLCA contain the SQLSTATE as five characters. Going back to the documentation:
An advantage to using the SQLCODE field is that it can provide more specific information than the SQLSTATE. Many of the SQLCODEs have associated tokens in the SQLCA that indicate, for example, which object incurred an SQL error. However, an SQL standard application uses only SQLSTATE.
So, it still seems fine, but then it turns out that SQLCODE 0 can have non-all zero SQLSTATEs!
New in the Documentation
At least for a few people this is a bit of a shock. From the SQLCODE 000 documentation:
SQLSTATE
00000 for unqualified successful execution.
01003, 01004, 01503, 01504, 01505, 01506, 01507, 01517, or 01524 for successful execution with warning.
Say What?
Yep, this is simply stating that you have got an SQLCODE 0 but up to nine different SQLSTATEs are possible… This is not good! Most error handling is pretty bad, but now having to theoretically add SQLSTATE into the mix makes it even worse!
What are the Bad Guys Then?
01003 Null values were eliminated from the argument of an aggregate function.
01004 The value of a string was truncated when assigned to another string data type with a shorter length.
01503 The number of result columns is larger than the number of variables provided.
01504 The UPDATE or DELETE statement does not include a WHERE clause.
01505 The statement was not executed because it is unacceptable in this environment.
01506 An adjustment was made to a DATE or TIMESTAMP value to correct an invalid date resulting from an arithmetic operation.
01507 One or more non-zero digits were eliminated from the fractional part of a number used as the operand of a multiply or divide operation.
01517 A character that could not be converted was replaced with a substitute character.
01524 The result of an aggregate function does not include the null values that were caused by evaluating the arithmetic expression implied by the column of the view.
Not Good!
From this list the 01004, 01503, 01506 and especially 01517 just jump right out and scream at you! Here in Europe, we have a right to have our names or addresses correctly written and, in Germany with all the umlauts, it can get difficult if you then have a 01517 but SQLCODE 0 result!
I hope you don’t find this newsletter too unsettling as, after all, Db2 and SQL normally works fine, but I do think that these SQLSTATEs should really have warranted a positive SQLCODE when they were first created…
What do you all think?
TTFN,
Roy Boxwell
Update:
One of my readers wonders how practicle these “errors” are. A good point, and so here is a nice and easy recreate for the 01003 problem:
CREATE TABLE ROY1 (KEY1 CHAR(8) NOT NULL,
VALUE1 INTEGER ,
VALUE2 INTEGER )
;
INSERT INTO ROY1 (KEY1) VALUES ('A') ;
INSERT INTO ROY1 (KEY1) VALUES ('AA') ;
INSERT INTO ROY1 (KEY1,VALUE1) VALUES ('B', 1) ;
INSERT INTO ROY1 (KEY1,VALUE1,VALUE2) VALUES ('BB', 1 , 1) ;
INSERT INTO ROY1 (KEY1,VALUE1) VALUES ('C', 2) ;
INSERT INTO ROY1 (KEY1,VALUE1,VALUE2) VALUES ('C', 2 , 2) ;
SELECT * FROM ROY1
;
CREATE VIEW ROYVIEW1 AS
(SELECT AVG(VALUE1) AS AVGVAL1, AVG(VALUE2) AS AVGVAL2
FROM ROY1)
;
SELECT * FROM ROYVIEW1
;
This set of SQL ends up with these outputs:
---------+---------+---------+--------
KEY1 VALUE1 VALUE2
---------+---------+---------+--------
A ----------- -----------
AA ----------- -----------
B 1 -----------
BB 1 1
C 2 -----------
KEY1 VALUE1 VALUE2
---------+---------+---------+--------
C 2 2
DSNE610I NUMBER OF ROWS DISPLAYED IS 6
---------+---------+---------+---------+---------+---------+-----
AVGVAL1 AVGVAL2
---------+---------+---------+---------+---------+---------+-----
1 1
DSNT400I SQLCODE = 000, SUCCESSFUL EXECUTION
DSNT418I SQLSTATE = 01003 SQLSTATE RETURN CODE
DSNT415I SQLERRP = DSN SQL PROCEDURE DETECTING ERROR
DSNT416I SQLERRD = 0 0 0 -1 0 0 SQL DIAGNOSTIC INFORMATION
DSNT416I SQLERRD = X'00000000' X'00000000' X'00000000' X'FFFFFFFF'
X'00000000' X'00000000' SQL DIAGNOSTIC INFORMATION
DSNT417I SQLWARN0-5 = W,,W,,, SQL WARNINGS
DSNT417I SQLWARN6-A = ,,,, SQL WARNINGS
DSNE610I NUMBER OF ROWS DISPLAYED IS 1
Hi all! Welcome to the end-of-year goody that we traditionally hand out to guarantee you have something to celebrate at the end-of-year party!
BPOOL
All Db2 releases since the very beginning of time have used Buffer Pools and when Data Sharing came along in DB2 V4 Group Bufferpools got invented. Since then bufferpools have always been with us and sadly no-one seems to really care about them anymore!
Checked?
When was the last time that you actually checked your local and group bufferpools? Have you really seen any problems? The fantastic thing about Db2 is that you can have 1000’s of problems occurring every second or two but it *still* just keeps on truckin’ !
Where to Begin?
I always like to begin at the beginning and so review where you are right now by downloading and running the SOFTWARE ENGINEERING BufferPool Health check program! It is an extremely light weight tool that you must simply run *locally* on each and every member and it simply lists out what it finds as being bad, horrible or evil!
Old Advice
Refer to my “old” blog to see what you could/should be checking and how bad it can really get as well.
Whaddya get?
The BufferPool HealthCheck is a one step program that simply lists out whatever it finds as being not good. At the end of the documentation is a table listing out all the checks it does. There is one important check it does *not* do and that is the cross-check between all local bufferpool sizes and the initial size of the related group bufferpool. That is just a little bit too complex for some freeware!
Want more?
If the results help you or you are interested in more, then our SQL WorkLoadExpert for Db2 z/OS product has a new separate licensable Use Case – Buffer Pool which contains all the checks plus the GBP Initial size one.
How does it look?
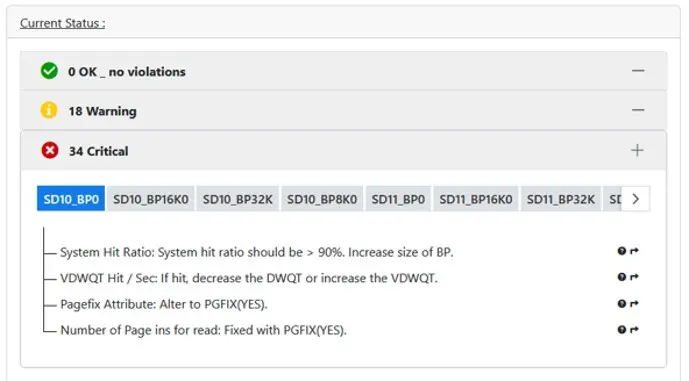
In this screen shot you see the list of Bufferpools being looked at and do you notice the highlights on a couple of tabs? Those yellow stripes should tell you that Bufferpool simulation is on in these two buffferpools. Simulation is really really good, it came in with Db2 11 but most people missed the launch event! Check it out as it is really good but beware! Do not simulate three or more Bufferpools at the same time!
Order By?
The order that you see is the importance list. In my humble opinion this is the list of KPIs that should be worked on from top to bottom and there are more than on this screen grab!
Fixes?
On the right-hand side, we then show you which corrective action is required, if any, to get the bufferpool running better, faster and cheaper!
On the overview highlights we list out what is Good, Bad and Ugly with direct links down to the details. Here will also come a ranking and a highlighting of the Tab to drag your eyes to the problem children that you undoubtedly have!
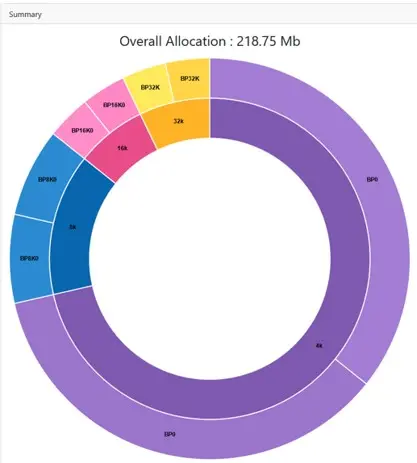
Here finally is then the first “top down” view of all your local bufferpools so that you can quickly see the sizes and usage of your bufferpools
Naturally it all looks better in RL!
I would dearly love to hear from any of you who run this software and get before and after reviews! I am 100% sure that buffer pools and especially group buffer pools are simply being ignored these days!
This month I want to run through all the purely SQL changes that we have received in Db2 12 and in Db2 13 right up until Db2 13 FL504. I was reading about agile development and how fast the deliveries are and so I wondered how many purely SQL changes have we, as SQL Users, actually received over the last six to seven years?
Back to the facts…
Ok, in Db2 12 FL501 we got LISTAGG which was very cool indeed, apart from the fact that you could not use ORDER BY which irritated all the SQL developers I know quite a bit! IBM also created a whole bunch of Accelerator only “pass-thru” functions that I cannot ever use as I do not know whether or not any of my customers actually has an Accelerator… so, for me, they do not really count. In total 28 BiF’s either got pass-thru or extra Accelerator support so if you *have* an accelerator good news indeed! This was all enabled over Db2 12 FL Levels 504 and 507 as well as APAR PH48480.
Uniwhat?
A bunch of, for me, weird things were the UNI_60 and UNI_90 support added to LOWER, TRANSLATE and UPPER for both Db2 12 and 13. There must be a use case out there but I am lucky enough not to have found it yet!
Super MERGE
MERGE got a major overhaul in Db2 12 with the addition of DELETE support but the story of MERGE did not end there! It still had a major performance problem if any of the index columns got updated as then it was forced to fallback to a tablespace scan. With Db2 13 FL504 (APAR PH47581) this problem was solved – nearly…
The following conditions must be met to enable Db2 to use an index for a MERGE operation when index key columns are being updated: – The MERGE statement contains a corresponding predicate in one of the following forms, for each updated index key column: index-key-column = literal-value, where literal-value is a constant or any expression that can be treated as a literal, including a host variable, parameter marker, or non-column expression. index-key-column IS NULL – If a view is involved, WITH CHECK OPTION is not specified.
Db2 SQL Reference
MERGE has basically become one of the most powerful SQL statements out there and you can actually cause terrible trouble if you use DRDA with VALUES clauses and hard coded “FOR 10 ROWS” style of SQLs. All is very well documented and worth a read under the heading:
DRDA considerations when NOT ATOMIC CONTINUE ON SQLEXCEPTION is specified (or the NOT ATOMIC CONTINUE ON SQLEXCEPTION clause is not specified and source-values (VALUES) is specified)
Db2 SQL Reference
This Db2 13 APAR also enabled the chance of getting List Prefetch as an access path which is, as far as I can tell, the only “new” access path in Db2 13.
Pagination anyone?
The use of OFFSET was a great innovation for Db2 but the “other” pagination was better! I mean data-dependent pagination which changed this old chestnut of an SQL:
WHERE (LASTNAME = 'SMITH' AND FIRSTNAME > 'JOHN')
OR (LASTNAME > 'SMITH')
Into this modern SQL:
WHERE (LASTNAME, FIRSTNAME) > ('SMITH', 'JOHN')
Much much better and for online generated dynamic SQL, I am talking to you CICS, a fantastic win! To verify this you get a range-list index scan “NR” in your ACCESSTYPE PLAN_TABLE column when you EXPLAIN it.
One at a time please
Piece-wise DELETE using the FETCH FIRST nnnn ROWS was also a really good idea instead of causing possible lock escalations and/or timeouts. A simple loop around the DELETE statement and Bob’s your uncle!
Db2 13 – What’s New?
The big stuff here was the extension of the PROFILE table (I keep talking about it don’t I?) as now it also handles Local things – This is a game changer! Starting with CURRENT_LOCK_TIMEOUT & DEADLOCK_RESOLUTION_PRIORITY but I am sure this list will grow and grow. The PROFILE table is just way to good not to use these days!
AI got a major boost
We got a bunch of AI stuff in Db2 13 (SQL Data Insights) but the first new “agile” one was in FL504 when AI_COMMONALITY was released. It will hopefully enable shops to find outliers in the data which were not there at training time.
Db2 V8 finally done!
Finally, the last thing that was started way back when in DB2 V8 was done! The length of a column name has been expanded from 30 up to 128 bytes. However, do not do this! The SQLDA is *not* designed for this and so it might look nice on paper but, depending on how you interface to them, it might cause serious grief!
Lower cadence higher quality
IBM have announced a cadence of two FL’s per year down from the 3 – 4 when Agile all started and so I am happy that the list of changes will keep getting longer and the quality of the code higher.
Just SQL!
Please remember all I am talking about here is SQL relevant enhancements – there are tons of others as well – just think about Utilities or FTB etc. etc. For a full list always download and read the latest “What’s New?” guide.
Did I miss anything? Drop me a line if you think so!
Ahhh! So good to get back on the road again… I am now back to my pre-COVID travelling and it catches up with you! I am soooo glad that I only have the German GUIDE in December and then I have *no* more planned travelling this year – Hoorah!
I have not heard of any outbreaks of COVID from IDUG yet, unlike TechExchange where I heard a bunch of Champions all got the lurgy again…
Back to Tech Stuff!
Tons of really good technical talks all started for me on Sunday already, as I flew in to Prague
I met “The Usual Suspects” at the hotel bar, including Julian Stuhler who was there, as a retired guy, to hold the keynote on Monday morning. We had a nice night chatting and drinking. Then early the next day, off I was to the Prague Conference Center (PCC) to register and get the booth built.
Once there, I met the dynamic duo! Dan had flown in after winning Best Speaker at the IDUG 2023 NA and it was great to see him, and Denis, again!
Of course, as I was busy building the booth, I missed Julian’s key note but I heard it was very good indeed. I hope that someone uploads the PDF to the IDUG site so I can actually read what he said! I heard that it was all about Past, Present and Future – the Evolution of Db2 and IDUG and it must have been really good as it overran and was full!
Due Diligence
Please remember two important things:
1) To get the links to work you must be registered at IDUG *and* entitled to the content. Otherwise you will get a “forbidden” screen popping up! If that is the case you can then think about buying the “Premium” version of IDUG membership which does allow downloading of conference files without having to wait around two years.
2) I am only one person, so I did not get to see every presentation at the IDUG. If the presenter was swapped or the session cancelled I might not have caught that, so I apologize if I have forgotten anyone or anything!
Track A is Where it Always Starts!
A01 with Haakon Roberts doing his usual fantastic stuff about Db2 Past, Present and Future. For me, the highlight was the Db2 13 FL504 new Built-in Function (BiF) for SQL Data Insights (SQL DI) AI_COMMONALITY that I had seen rumors about but now it is coming this month! UPDATE! Now Available, Dec 2023
A02 was Akiko with a 40-Year review of performance, including some very nice comparisons from the IBM Benchmarks of 13 years ago and today. Amazing how fast things get in just 13 years – 4.2 times faster but with 2.5 times more logging! Another nugget from this was that SQL Data Insights goes into fake parallel mode to enable ZiiP eligible workloads…
A03 was Haakon again, this time showing us the Past, Present and Future of schema evolution. My take-away from this, is due to moving from multi-table tablespaces (Think QMF here!) you might well start running out of OBIDs in your Database. We at SEG have a Migration Health Check that tells you if you are indeed going to be knocking on the door of some nasty internal limits!
A04 Rotate away your problems from Johan Sundborg. This includes nearly all the JCL you need to set-up and run Partition Rotation for your good candidates. You can save massive amounts of CPU if you have the right Use Case.
A09 Establishing Db2 recovery procedures using redirected recover. A very good overview of doing RECOVERY using REDIRECTED as well. A good list of nasty little APARs where “old” table defs can get ya! Plus, a page about Rookie mistakes…
A13 Monitoring your distributed workload for Db2 for z/OS. This was all about the fascinating world of trying to figure out who is connecting with which type and version of connector to your Db2 sub-system. A brief overview of the new IFCIDs 411 and 412 with the very good data that they have is also included. A bunch of example SQLs rounded off a very good presentation indeed!
A15 Implicitly or Explicitly Defined Db2 Objects the Good, the Bad and the Ugly. Steen doing his thang! A good detailed look at the pro’s and con’s of implicit spaces and the many pitfalls of PBGs with LOBs – I avoid them at all costs!
A16 How to avoid the loss of data and minimize the costs associated with a Db2 outage. Top tips all about Backup and Recovery. Including the separation of catalogs that is required for successful BACKUP SYSTEM.
A17 Sun Up to Sun Down The Chase to Achieve 24-7. This was a peek into parallel sysplex and how to guarantee you do not fail! Also includes a bunch of Db2 13 enhancements for continuous availability.
B02 The A-Z of Logging for Db2 for z/OS explained everything about what is on and not on the Log and really contained an A to Z list. However, the values for J, K and Y were missing – Perhaps my trusty readers can come up with some values? E.g. J – JCL, K – KB and Y – Yottabyte! Further to this, we have at SEG another freeware that reads your archive logs and tells you what you have! You may well be surprised at the amount of stuff that gets logged!
B04 A day in the life of a Db2 for z/OS schema was a really nice explanation of schema life from three different perspectives: Developer, DBA and System! Pretty neat!
B05 Reorg Rabobank biggest Db2 table from APN to RPN. A really good real-life story about REORGing epically large tables. My highlight, was the fact that the elapsed time output of the reload message “rolls over” after 99 hours!!!
B06 Db2 For z/OS and Unicode – What you need to know. A complete review and overview of the ever-present Unicode code pages that are always with us all these days!
B07 Getting Ready For Db2 13 – Updates. This was a review of Db2 12 Agile, continuous delivery and the steps required for a painless migration to Db2 13.
B08 Measuring is knowing – Db2 for z/OS instrumentation enhancements you may have missed. A very nice recap of all IFI changes in the past few years and also Commands and message changes. Please note that “Miscellaneous” was about 50% of the presentation!! Great data here and a reminder about being careful about RID overflows not actually being RID overflows.
B09 Who’s afraid of DDF? An explanation about DDF and how to get a handle on it. Another call to arms about using the PROFILE functionality (One of the best kept secrets in Db2 for z/OS IMHO!)
B10 “Run it Back” Db2 for z/OS All new “2023 SWAT Tales” Was another great list of things from Anthony which you all should be doing. Included is a great visualization of Cyber Resiliency/”Safeguarded” Copies which we did not even need a few years ago! A very important point that he mentioned, is the PTFs that we must all apply. I can happily recommend you subscribe to my APAR Newsletter where I update, every month, all the APARs of interest including HIPER and PE ones! Just go here to see the latest and, if you want to, you can then register for email updates:
B11 Db2 13 for the production DBA. Has three points for the DBA today. PBG – PBR Conversion. DDL break in using the PROFILE tables again. Finally, Dynamic Query Stabilization. Great stuff!
B12 How to Hack Db2 for z/OS – Lessons Learned from Mainframe Hackers. That grabbed your attention didn’t it? Slide 19 makes me laugh every time I see it! Seriously, the major problems are allowing uncontrolled access to APF load libraries (This has been true for decades of course, but these days with the new twist of USS +a usage! Slide 55 is extremely useful here.) the use of Magic SVCs (These I have used in the past…) and basic user id protection.
B13 Modernise your Db2 Environment – Top 20 Features People are Still not using. Adrian doing a great job of reminding us of what we have but are stubbornly ignoring! Slide 21 contained a very simple way of seeing if Parallel Access is for you! Slide 31 also reflects my opinion with RAM availability on z/OS. I am sure we (the DBAs) have much more RAM available than we are aware of. It can be *much* better used as an increased size for your buffer pools! Then slide 34 showed the real benefits…
B14 Recovering to another subsystem with DSN1COPY. Sadly, not available at this time. A09 is lurking here!
B15 Db2 13 for z/OS: What is new in Security and Compliance? All about SMF type 1154 and its usage in compliance. Then the use of various caches within Db2 for Authorizations finally discusses PROFILE tables again!
B16 When reality “derails” capacity planning for Db2 zOS. No link available yet, but it is in the zip file as a download. My mantra – slides 26 – 35! Especially slide 35…
B17 Db2 13 for z/OS Utility History :What is it and how to use it. All about the new Utility History table and example SQLs about how to use it.
E04 Fun with Ansible and Db2 for z/OS. If it is possible to have fun… A ton of examples, tips and tricks etc. If you are going down the road of Ansible this should be your starting point!
E08 Db2 Analytics Accelerator – What is New, what are customers doing with that! Hard numbers and data from real life customer usage of the Accelerator. The performance boost of NVMe is impressive! Ending with a sneak peek at 7.5.12.
E11 Successfully migrate from CDC to Integrated Synchronization IBM Db2 Analytics Accelerator. A nice plan to migrate from CDC to InSync, listing out the steps to take and how to get there.
E12 It’s AI Jim, but not as we know it! My little presentation all about the Hype and the Reality of AI and then showing how useful the three (four!) SQL Data Insights Built-in Functions that are supplied free of charge with Db2 13 for z/OS are.
E13 Db2 and the Magic of Disk – This was all about Disk I/O from way back when to today. Very interesting indeed. Gotta try and reserve a table at Katja’s restaurant one day!
E14 Db2 for z/OS and LUW Big Buttons for Application Performance. DanL strutting his stuff and basically trying to get us to reduce the number of SQL calls or the number of SQLs by using joins, views etc. as these are, by definition, the best way to save time and cpu!
E15 ‘The Art of War’ against Bad SQL. Cool title indeed! A very good presentation with real world examples about how simple changes can save mega-bucks – Plus plenty of cool quotes!
E16 Accelerator on Z Monitoring and workload assessment update. A review of how to monitor the Accelerator(s) you have and make sure enough disk and memory are available and used!
E17 How to Drive Down Database Development Dollars. An absolutely wonderful mix of tips and tricks in a wide variety of languages, all about getting more performance and less pain out of your system.
F05 SQL on Db2 for zOS: The Missing Parts and how to deal with them. Thomas lists a few SQL challenges he has had, how he solved them and how he would *like* them solved by IBM development! There is also a nice list of AHA! Ideas you may wish to vote for.
F07 Db2 13 Application Development Topics. Gives a great review of Db2 13 and what SQL changes are contained within as well as PROFILE table again! Get the hint? Included at the end are 12 pages all about the “history” of SQL fitting in to the overall theme of “40 Years”
F08 The Business Value of Db2 SQL Data Insights. All about how to use the SQL DI in a real business case. Starts with football but ends with an Insurance Case. Well worth looking into for the examples contained within!
F09 Application Modernization – Considered those Db2 for z/OS Capabilities? Going modern but incrementally. She showed how many JAVA, Python, node.js and Go developers there are out there… Loads! As a bonus it mentions PROFILEs again…
F11 Lessons learned while enabling DDF in an existing Db2 Datasharing environment. A good way to show how to set up DDF including security and log performance. The recommendations for application name and accounting to be used are very good and I can also recommend it! It is the *only* real chance to see which application is connecting to your host Db2 subsystem! Guess what? They also used PROFILE tables ….
F12 CLPPLUS : The Other Db2 Client. A cross platform presentation and it contains what you need to know about getting LOAD on z/OS to work from LUW. Very cool and thin – unlike me …
F13 Back to Basics with Db2 buffer pools. This is a great intro and explanation of buffer pools. What they are, what to look for and what to do! I held a vendor presentation P06 which covers *exactly* the same ground! My vendor presentation is here:
F14 Encrypting Db2 Connections with TLS/SSL. Everything about TLS/SL – It gets really interesting for z/OS people around slide 15 when “keyrings” get mentioned! Slides 41 to 44 are also very handy for trouble shooting.
F16 Get Cozy with Ansible for z/OS. Apart from having the absolute coolest session code of the IDUG, this was all about going Ansible on the Mainframe. This is an introduction into the world of Ansible automation on the mainframe including all that goes with it. Impressive stuff!
F17 Rock & Roll with Db2 for z/OS “Hey Db2, suggest music like zzTop” – This was a deep dive into SQL Data Insights on z/OS using Spotify as an example. It also shows the internals of the ML system used. It finishes with a “call to arms” to get other people interested in the Host side of things. Slide 19 is very handy for all the Prereqs you will need.
G01 Database Design Basics. An excellent intro into DBMS’s and very good ideas about design especially for OLTP and OLAP and, one of my faves, naming standards for columns and tables!
G02 The Basics of SQL Queries: From Fetches to getpages and I/Os. Basically, an SQL 101 but contains a lot of good data. The use of buffer pools is well explained and how they can really help (see earlier presentations!) Strangely PROFILEs were *not* mentioned this time!
G03 DB2 SQL – go beyond the usual – My current TOP 40 SQL tips, tricks, and opinions. Brian gave a great presentation about the modern features of SQL that you all should be using! Well worth reading.
G04 Advanced Db2 Performance Tuning for Beginners. Joe doing his usual great work of showing how to really do SQL tuning. I especially liked the Filter Factors page!
G05 Back To Basics Real Time Statistics: What are they and how are they used? Another 101 style presentation but this time covering everything about the RTS tables and how you can, and should, use the data within.
G10 IBM watsonx.data & Db2 Warehouse: Scale analytics and AI across the enterprise. All the low-down about watsonx including the “new” governance part that we will all need to get full transparency.
G15 Db2 for z/OS administrative tooling strategy : Customer feedback, Roadmap, future direction & DEMO!! Naturally no demo here, but I am sure you can request one! All about Admin Foundation and the EOS of Data Server Manager in March 2024. It then went on to tell us why we should all be using Visual Studio Code and then adding in all the various extensions (Db2, SQL, COBOL etc. etc.). Here lies the future!
G16 Db2 AI for z/OS Strategy and Technical Deep Dive. Akiko took us on a tour! The two AIs out there now for Db2: SQL Data Insights (For free) and Db2 AI for z/OS (Not for free) now at version 1.6 and the latter was the topic that was discussed including System Assessment.
G17 Db2 and Zowe. Everything, everywhere at once ! A run-through of Zowe over the years and also Developer extensions. If you are starting down the road of Zowe or Admin Foundation and Visual Code this is a good starting point!
It was another really good IDUG with loads of excellent and interesting z/OS sessions. I hope to see you in Valencia in 2024 for EMEA or Charlotte for NA !
Please remember: You must be authorized to access the IDUG data and if the links fail please contact IDUG and not me 🙂
TTFN,
Roy Boxwell
Cookies facilitate the provision of our services. If you don't accept cookies, certain features of the website are not available. Further information can be found in our privacy policy.AcceptRefusePrivacy Policy