Hi all! Now safely back from Philly and, as ever, I learned a lot there! Already looking forward to Praque and the EMEA IDUG this October.
As always, I have listed out all of the Db2 for z/OS presentations I could find and added a few review sentences to them. Any links herein require you have a password and userid at IDUG with the required rights to access the data. This means you must have been either an attendee or virtual attendee with full access – Just being a member of IDUG is *not* enough!
SP01 | Db2 for z/OS Update: The Latest From The Lab
Speakers: Akiko Hoshikawa, Haakon Roberts
A01 | Data Fabric in 60 mins for Db2 for z/OS DBAs!
Speakers: Cuneyt Goksu
Data Fabric is one of the trend topics in IT Industry as part of Digital Transformation. This session summarizes both architectural, use case and product level discussions in the context of IBM Z and Db2 for z/OS Eco system.
This contains some great info about secure ports, certificates and the use of system profiles for remote access.
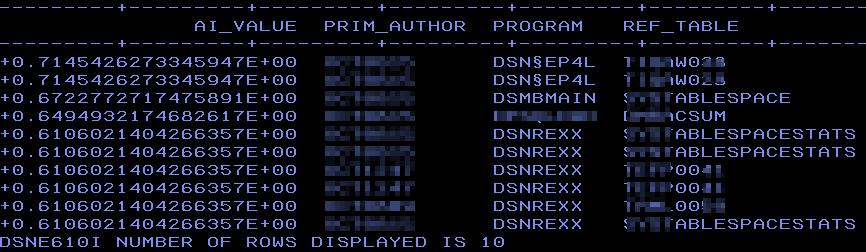
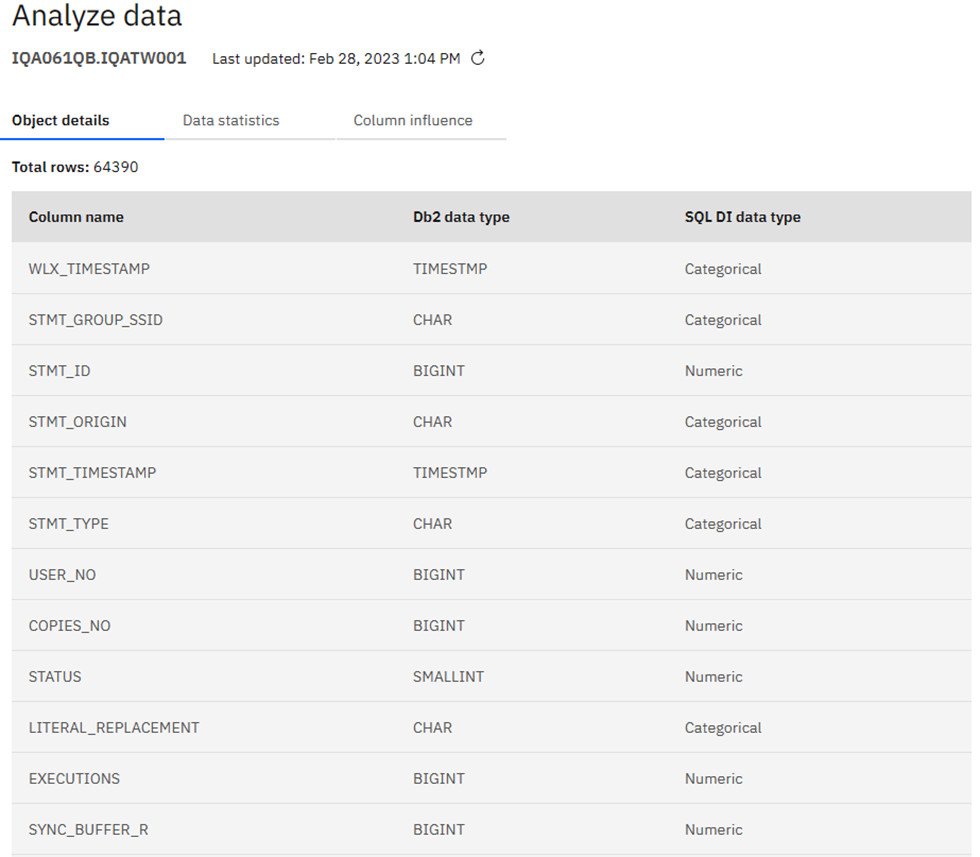
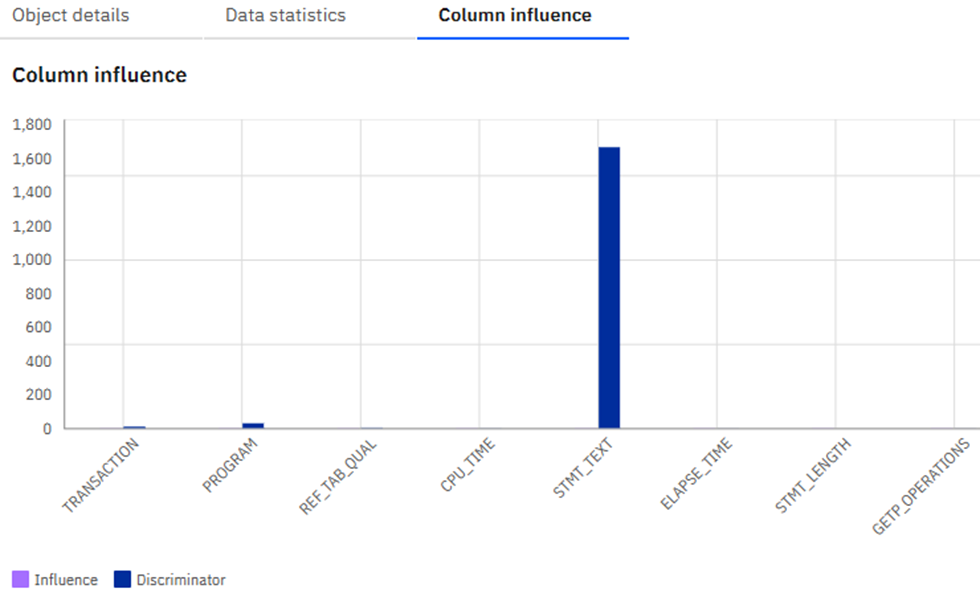
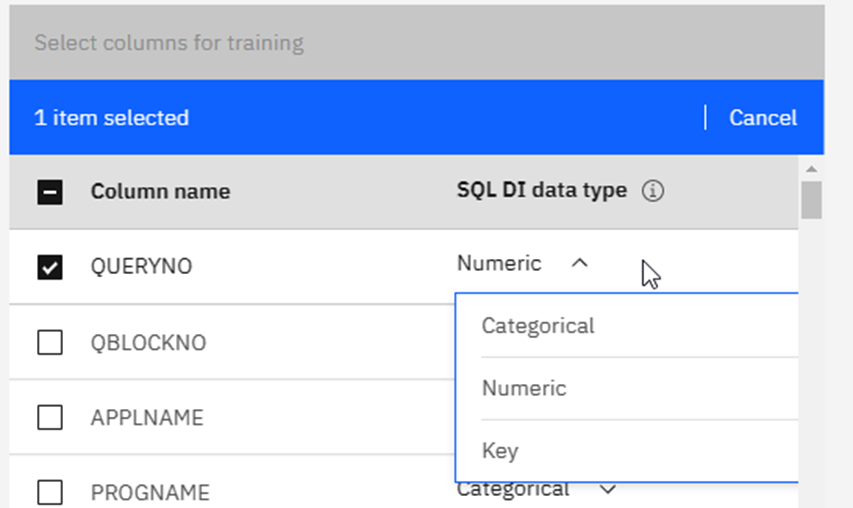
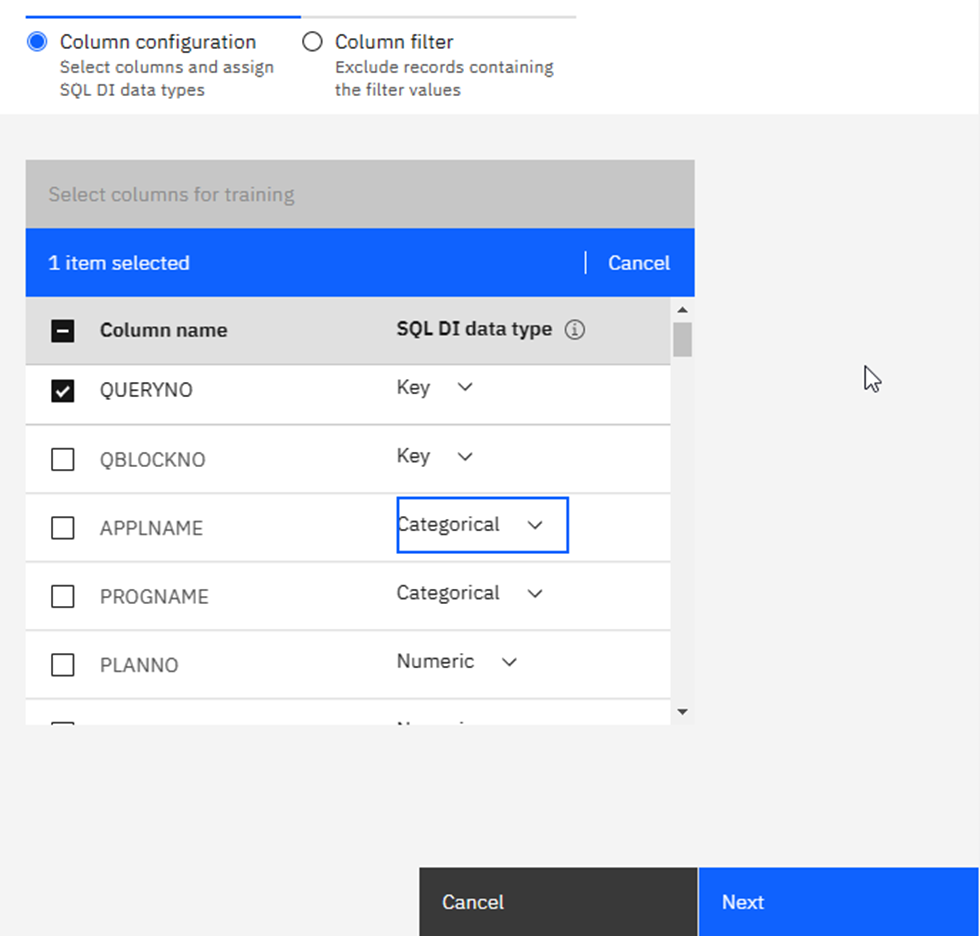
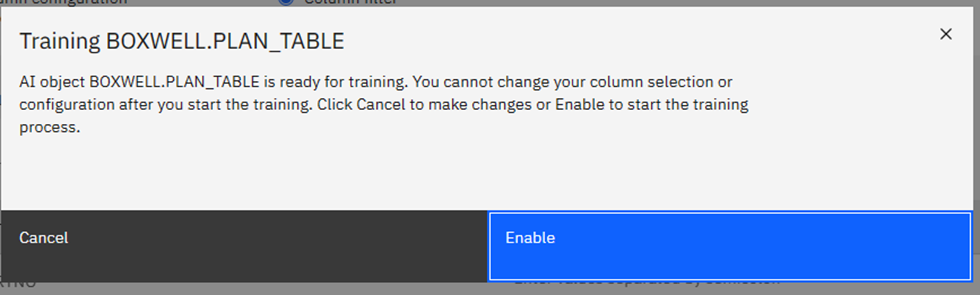
A02 | Who does that? Using SQL Data Insights to spot unusual behavior
Speakers: Mike Behne
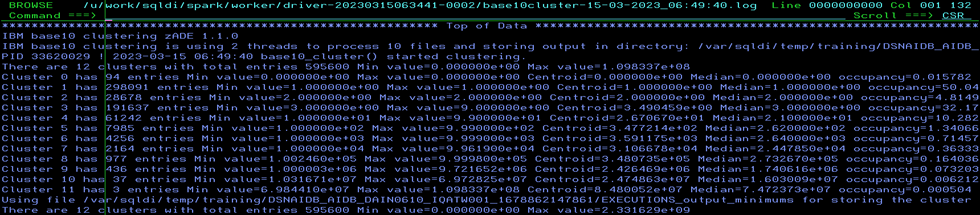
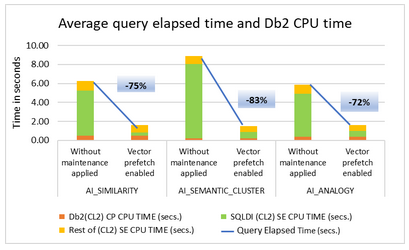
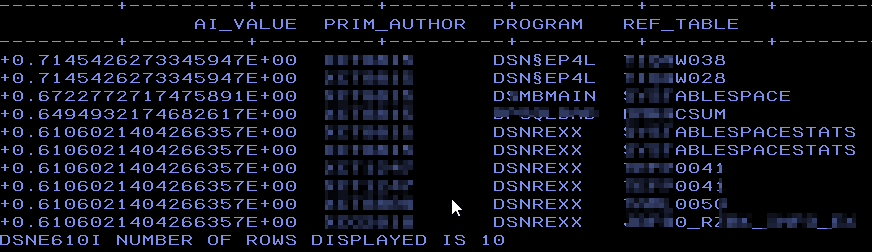
This session explores SQL Data Insights (SQLDI) capabilities, reporting on early efforts to apply SQLDI to learn more from available data.
Basically, saying what I found as well: Training is expensive and you gotta “Know your data” before you really start!
A03 | Db2 for z/OS Utilities – The Very Latest News
Speakers: Haakon Roberts
The Db2 Utilities team continues to deliver significant new function, availability and performance improvements after the GA of Db2 13. This session will cover the very latest developments and also look forward to some of what you can expect to see later in 2023.
As usual a great presentation with all the newest stuff you just need to know! This included a free 30 minute long power outage which didn’t fluster Haakon at all! However, it caused Chris Muncan to motor through his next presentation!!
A04 | Recovering to another subsystem with DSN1COPY
Speakers: Chris Muncan
Ever have a major production problem that you didn’t know about and found out a month later and need to restore the data but to not restore on top of production? We did and here’s how we did it!
World record speed speech about DSN1COPY – Quicker than SSDs!!! Due to a small mistake in the timing app Chris thought he had even less time than he already had… He told me the session would be re-recorded at a saner pace! Even so, there were glorious nuggets like the requirement to issue the ALTER xxx-xxx ADDVOLUMES( * , * ) which catches people out all the time these days!
A05 | Data Modernization: Embrace the Mesh!
Speakers: Greg DeBo
Data Mesh is the new hot term for Data, I’m gonna talk about how to integrate mainframe data into your Data Mesh.
This was all about moving or not moving data around. Especially interesting was all the IMS stuff! Still nailed to its perch!
A06 | Db2 for z/OS Performance Latest Updates
Speakers: Akiko Hoshikawa
The latest performance and capacity planning updates from Db2 for z/OS (both Db2 12 and Db2 13) as well as IBM zSystems updates that you could take advantages of. The session will explain the key items with the reference of instrumentation updates to evaluate the features.
Aikiko with the normal list of great and good things. Heads up for the CFLEVEL 25 level size change. You had *all* better check your CF Sizes!!!
A07 | Use profiles to monitor and control Db2 application context
Speakers: Maryela Weihrauch
With increased popularity of distributed applications, related Db2 system and application definitions were defined in distributed application servers. Sub-optimal definitions could impact on overall Db2 health. Db2 z/OS provides capabilities to create profiles to monitor and control various aspects of a Db2 specific system and application contexts in Db2 profile tables. Db2 13 extends the profile tables to new attributes for local and remote applications. Maryela will review existing profile capabilities and introduce Db2 13 extensions as well as discuss use case examples.
Reviewed all about system profiles and some use cases to stop DoS attacks – Good stuff!
A08 | Best Practices for Applying Db2 for z/OS Software Maintenance
Speakers: Robert Tilkes
Discuss best practices for Db2 for z/OS maintenance strategy, SMP/e environment configuration, patch management and deployment.
All about applying fixes, rsus and hipers to Db2 for z/OS and the sad fact that we are *all* behind here! Included some nice sample JCL at the end to check your own SMP/E system.
A10 | Db2 13 for z/OS install and migration using z/OSMF workflows
Speakers: Sueli Almeida
In this session we will demonstrate how you can exploit IBM Z/OSMF workflows to install and / or migrate a Db2 subsystem or members of a data sharing group. We will illustrate how the workflow artifacts are created. Next, we will show these artifacts are assembled into a workflow. Finally we will show how the execution of the workflow progression can be tracked or monitored.
A very brave idea, in my opinion, of automating Db2 upgrades and deployment using z/OSMF.
A11 | Migrating to Db2 13
Speakers: John Lyle
Presenting the Db2 13 migration process. Note: This was a top 10 presentation at IDUG EMEA. I’ve improved the content and added some new detail.
All about getting there, including the new -DIS GROUP DETAIL output to help you see “where you are”.
A12 | Copy up – Buttercup
Speakers: Chad Reiber
Presentation about Db2 z/OS image copies. The how’s and why’s image copies are important. What and when they should be taken.
Absolutely everything you were afraid to know, but asked anyway, about COPY!
A13 | Db2 Attachment Facilities – Advanced Topics
Speakers: Emil Kotrc
Db2 Attachment Facilities are the interfaces between the application programs and Db2 for z/OS. In this presentation we will go through the basics of the most common attachment facilities, we will show how and when to use them, and we will also cover some advanced topics such as security implications, thread reuse, connection switching.
A deep deep dive into Db2 attachment details! Contains even assembler examples…
A14 | Db2 Logging Basics & Exploitation Beyond Recovery
Speakers: Steen Rasmussen
This is a “beginner” session describing why the LOG is one of the crucial components of Db2 and cover some log basics of what the log contains as well as get an understanding of how the log can be exploited for other tasks.
Steen introduces the Db2 log and how you can use it (or better yet buy a log analysis tool and let it do the work!)
A15 | Database Administration Enhancements of Db2 13 for z/OS
Speakers: Robert Catterall
This session will focus on the Db2 13 enhancements that pertain to database administration: online conversion of PBG table spaces to PBR, online removal of active log data sets, profile table support for local-to-Db2 applications, instrumentation improvements, and more.
Robert ran through all of the goodies in Db2 13 that could impact DBAs, including the new insert logic for PBGs that had always annoyed me in the past!
A16 | Who’s afraid of DDF
Speakers: Toine Michielse
For those who are being confronted with DDF workload, this presentation will discuss pitfalls, new resources to monitor and tune and application changes to be considered.
Highlights of using, and getting better performance from, DDF to connect.
B01 | Db2 Analytics Accelerator – Newest Enhancements
Speakers: Eberhard Hechler
This presentation is discussing the newest functions and features of the Db2 Analytics Accelerator, such as enhancements of the IBM Integrated Synchronization (InSync) engine (e.g., ALTER TABLE ROTATE PARTITION support), query acceleration improvements (e.g., ability to add Db2 unique constraints on the Accelerator), collecting actual explain information, Db2 Analytics Accelerator on IBM zSystems enhancements (e.g., improved I/O performance and reduced CPU consumption), reducing overall trace collection time, new and enhanced stored procedures, and administration enhancements. The presentation ends with an outlook to future enhancements.
This was all about Accelerators, specifically 7.5.8, 7.5.9 & 7.5.10 in this case!
B02 | Back to basics – Real life battle experience
Speakers: Joe Huang
I am currently training 3 junior z/OS DBAs in our company on various DB2 topics. I like to combine 6 of the training material into one and make a 60-minute presentation for the beginner or semi-seasoned DBAs.
Excellent real world experiences including work files, and all the ZPARMs involved as well as unique rowid pitfalls.
B03 | DBA’s Epic Journey
Speakers: Leila Hosseini
There are lots of performance tuning hints that we are aware of. Maybe we read the IBM Manuals or IDUG resources that we can leverage as a possible solution to our issues. As a DBA all of us know lots of performance and tuning tips and tricks , but when Unexplainable performance degradation happens! What would be a DBA’s reactions? It is the Art of DBA to put together all his/her knowledge and observations , analyze the situation and Resolve the issue.
A DBA needs to find out answer for following questions:
1-what is the main cause of the issue?
2- how it could be resolved?
Real world SQL tuning experiences and problem solving. With four example super bad SQLs and how to fix them up!
B05 | Db2 13 Early Customer Experiences
Speakers: Anthony Ciabattoni
The presentation will concentrate on Db2 13 early customer experiences discussing what went well, what they liked and also the things they wish they knew and could have avoided.
A quick run though the pre-reqs of Db2 13 and then some of the highlights including correct amounts of copying to avoid ransomware style attacks.
B06 | Db2 Utilities in Practice
Speakers: Hendrik Mynhardt
This session will cover not just what is new, but also how to apply best practices for all your Db2 utilities in a real environment.
Lots of data about the new SYSUTILITIES table including reminding us to clean it up! Followed by a run-through of the big utilities and how they have been enhanced recently.
B07 | Db2 12+/13 for z/OS Database Design and Application Performance: Features and Usage
Speakers: Susan Lawson
With every new release and function level, (12+/13) of Db2 we look to see what features will allow us to improve the capabilities and performance of our existing applications as well as the availability of our data. We also have to plan to utilize new features in our development efforts.
Great to see Susan again as she is one of my favourite presenters. A ton of info in the presentation. Well worth a read afterwards!
B08 | Back-To-Basics: Table Space and Index Fundamentals
Speakers: Louise Comeaux
A review of the various types of tablespaces and the indexes that are defined to them.
A very nice run through all current DB, Tablespace, table, and Index types including PBR RPN, DPSIs etc. Note that LOB and XML were not covered as this was, after all, a back-to-basics presentation.
B10 | When Microseconds Matter
Speakers: Thomas Baumann
Imagine a well-tuned Db2 z/OS SQL workload where the most frequently executed queries use 50 microseconds CPU per query or even less. Is it worth further tuning? And what are the tuning techniques to be applied? This presentation starts at exactly that point and – without touching the SQL query text – demonstrates how another 10% of CPU resources were squeezed out of that workload. And we will also discuss at what point we can truly decide that a query runs at maximum speed and no further tuning is possible.
All about squeezing more juice out of that lemon! Great example methodology and example SQLs make it easy to start doing this all!
B11 | Db2 for z/OS 101: Buffer Pools and Group Buffer Pools
Speakers: Mark Rader
Are you new to Db2 for z/OS? Or new to Db2 for z/OS data sharing? Want a refresher on buffer pools? Buffer pools, and group buffer pools for data sharing, are key to supporting Db2 workloads. Come learn the basics for these important resources.
Great four-way presentation with really good visualization. Played to a packed house and was very well received. More presentations like this please!
B12 | Db2 for z/os System Profile, The New ZPARMs and More!
Speakers: Paul Bartak
A practical look at implementing Db2 system profile rules to customize your experience with Db2 for z/OS. I started presenting on Db2 System Profiles with Db2 10. This presentation will cover updates through Db2 13.
Another presentation talking all about system profiling. It is one of the most under-used fantastic features of Db2 so I fully understand this!
B13 | Large tables – Obstacles and Strategies to win!
Speakers: Scott Walker
Data is ever growing and challenges with large tables make our jobs more difficult. Success with these monsters is imperative. Everything matters with table design/maintenance. Perhaps you are stuck with an old design that is not prepared for influx of data or you’re building a new table and want to build something scalable and low maintenance. I will give you a few items to consider as well as pain points I’ve lived through. Additionally, this session will be interactive – audience participation will benefit the conversation.
An intro and exposé of all things HUGE in Db2! Tips and tricks included!
B14 | Monitoring your distributed workload for Db2 for z/OS
Speakers: Jørn Thyssen
Distributed workload is becoming more prevalent, and for many customers it is a significant part of the overall Db2 for z/OS workload. In this session we will explore the various options available with Db2 for z/OS to understand and monitor your distributed workload. Our focus is on the system side to help you protect your Db2 system.
This introduced all the new and varied ways of seeing from where remote SQL is coming from and a nice set of ways to check if your drivers are up to date.
B15 | Things About Db2 for zOS I Wish I’d Remember When….
Speakers: Michael Cotignola
This presentation will cover some of the more overlooked or forgotten options, commands, syntax that could prove to be invaluable in managing your Db2 environment. Intended target audience is for people new to Db2 for zOS, application developers who may benefit from knowing more about the internals of Db2, or people like myself who just can’t remember a command, syntax or option and need a refresher.
A nice stroll down the, sometimes unfamiliar, road of things we forget or use very rarely.
B16 | Db2 13 for z/OS Application Management Enhancements
Speakers: Tammie Dang
Application development and management are always important topics with Db2 for z/OS due to the complex process and volume of applications exposed on the platform. Certain legacy applications are difficult to change and all changes to applications typically require following a strategic process from development to test,before deploying to the production environment. In a cloud environment that hosts multi-tenancy, applications are typically different in characteristics. These applications can each access different database objects and have their own concurrency requirements and toleration.
You can now use Db2 13 to set application-granularity lock controls such as timeout interval and deadlock resolution priority to match the individual application’s need. And you can do this without the cost of changing the application’s source code. Db2 13 also introduces a mechanism to optimize for the success of DDL break-in without needing to duplicate versions of the application packages and without impacting non-dependent applications.
This presentation went through the new and changed options including system profiles again… You get the idea that people are trying to tell you something here??? Plus DDL break-in explained!
C13 | Db2 for z/OS availability, efficiency and application stability enhancements
Speakers: Frances Villafuerte
Db2 13 provides many new features to accommodate application workload growth and simplify processes for DBAs. This session gives you an overview of key features.
Started with a nice list of removed ZPARMs and which values they now have in perpetuity, then a list of changed ZPARM values so you can easily verify that you are not “living in the past” . My personal favourite is EDM_SKELETON_POOL from 51200 to 81920. I know of sites which still have 10240! Check out my blog about “Small ZPARM – Big effect!” https://www.segus.com/2017-04-db2-zparm-edmpool-size/ for details of what this ZPARM actually controls and enables! It is not really that clear from the docu at all! This was then followed up with all the problems with PBG spaces, including the horrible inserted empty partition problem, and how some of these problems are solved in Db2 13. John Campbell stated before he retired “MAXPARTITIONS 1 DSSIZE 64GB no other setting is good!”. Then it continued into the PBG -> PBR Migration scenarios as IBM, at least long term, want us off PBGs completely!
E01 | Optimization 101. What makes Db2 Choose Certain Access Paths
Speakers: Tony Andrews
This is a great ‚Back to Basics‘ presentation (and then some) for understanding the logic of the optimizer. The Db2 optimizer is a cost based optimizer estimating the cost of many possible access paths for an SQL query, ultimately choosing what it thinks to be the least expensive access path. But what determines the choices, and what makes one cheaper than another? Come learn the basics of the Db2 optimizer, and what you can do to help and influence its logic to the most efficient paths. Come learn the basics of performance tuning queries, programs, and applications.
Optimizer 101 introducing you to everything the optimizer uses to make its decision on access paths.
E02 | Db2 13 Application Development Topics
Speakers: Emil Kotrc
What is new in Db2 13 for application developers? Let’s explore these topics in this session. We will cover SQL related enhancements as well as performance improvements that application developers can benefit from.
This was a real potpourri of Db2 13 stuff! CD, Current Lock timeout, Profile tables (again!), SQL DI and APARs!
E03 | Taming Dynamic SQL with Db2 V12
Speakers: Steve Loesch
This presentation will contain an overview of the techniques to capture and observe performance of Dynamic SQL in Db2 V12 implemented at Navy Federal Credit Union. Navy Federal Credit Union has many mission critical applications using Dynamic SQL. Examples of Db2 features such as Dynamic SQL statement stabilization, creation of Dynamic SQL history, a cross reference of SYSDYNQRY tables and the DSN_STATEMENT_CACHE table, and a SQL statement that will show that a table is used in packages and/or SYSDYNQRY statements.
Was all about getting, explaining and tuning your dynamic SQL by looking at the use of stabilized queries.
E04 | Db2 Java High Performance Best Practices Volume X
Speakers: Dave Beulke
This presentation details Db2 and Java performance best practices and discusses how to optimize your processing to run 100x faster. Db2 design, partitioning strategies, coding best practices, java class frameworks and debugging/tracing practices will be presented that can immediately eliminate your bottlenecks and enhance performance. After this discussion you will be able to dramatically improve your Db2 access, Java runtimes, minimize CPU and quickly access/process billions of rows with the best performance possible.
I just loved the 13th and 14th slides… I am also not a fan of those “things”… If you want to tune Java on the Mainframe *this* is your best starting point!
E05 | Do your Db2z application developers like Python? Sure let’s build z applications using it!
Speakers: Sowmya Kameswaran
Python is one of the top programming languages in the world. It’s easy to learn; for DBAs similar to REXX; and has a robust set of libraries that enable delivering business value; specifically surrounding data rapidly and easily. This presentation will use a Python on z/OS with the python-ibm_db library; along with a few visualization libraries to provide some fun demonstrations that also show the power and ease of use Python.
The first 10 slides were just setting the ground for working with Python on z! Not really difficult, but different from what we as “Hostees” are used to methinks! However it contained some really cool stuff as well as calling Visual Explain!
E06 | Is it worth it to migrate CICS cobol app to Windows .net?
Speakers: Mateusz Ksiazek
The presentation will show the real production approach for migration from CICS Cobol application to Windows .net.
After seeing all the graphics, you have to really wonder: Was it all worth it? Naturally, it all looks more modern but you still have to pay the ferryman at the end of the day!
E08 | Db2 for z/OS and LUW Big Buttons for Application Performance
Speakers: Daniel L Luksetich
This is not A deep dive into application performance. It is the simple but huge right things to do to have a dramatic positive impact to application performance!
Dan gives his great hints and tips about general SQL performance here. Not doing the call, coding a JOIN, use of ARRAY types etc etc.
E10 | Db2 Developer’s Top Tens
Speakers: Tony Andrews
There are many areas of Db2 application development that developers, testers, business analysts, etc, should know about. This presentation lays out my top 10 for the areas that are so important in performance and developing a good application. Areas of importance being SQL tuning tips, programming tips, and of course performance and the Db2 optimizer.
This was another run through of everything optimizer and then lists of things to check and do or not do for SQL Tuning. Quite excellent!
E12 | Code Your Db2 Applications for Performance from the Start!
Speakers: Craig Mullins
Most developers do not seriously consider Db2 performance implications until it is too late. But there are best practices that can be used to build performance into your programs even as from the very beginning.
Craig gives his great explanations as to how to code for performance from the start.
E13 | Db2 SQL Performance for Application Developers
Speakers: David Morris
Db2 SQL Performance for Application Developers. Developers can learn Db2 SQL performance tricks and best practices. When working with DBAs, developers will write better performing SQL, know what an Explain plan is, optimize SQL queries.
A nice run through the do’s and don’ts of SQL for Application developers.
F01 | What Db2 can do; I can do too – first steps towards machine learning
Speaker: Toine Michielse
In this presentation I give an overview of software and ideas that can be used to get yourself started in exploiting both data and software in your day to day life.
This got all „snaky“ when Anaconda and Python re-appeared. But it was really all about first steps in Machine Learning!
F02 | Database Trends 2023 – Things Are Changing and You Better Keep Up!
Speakers: Craig Mullins
What are the predominant trends in 2023 that impact data professionals and their usage of DBMSes.
With over 350 different DBMSs out there this was a great review of the state-of-the-art! Slide 15 is my fave!
F03 | Encrypting Db2 Connections with TLS – what a Db2 DBA should know
Speakers: Christoph Theisen
The presentation shows what is needed from a Db2 z/OS and Db2 LUW perspective to set up TLS encryption successfully. The main focus is on the Db2 Client side but we also cover the most important server-side topics.
This was all about TLS, certificates, Keyrings and Key stores! Fascinating stuff! Slide 53 point one was my fave because it’s so true … Please note that Christoph was a little bit confusing in his page numbering… The Slide 53 is really the PDF slide number *not* the „slide number“ you see in his presentation…
F04 | Db2 SQL – go beyond the usual – My current TOP 40 SQL tips, tricks, and opinions
Speakers: Brian Laube
Modern SQL is a powerful tool on its own for the DBA and application developer. Keeping on top of modern SQL techniques and functionality lets us move beyond the usual comfortable SQL. The presentation will go over my top SQL tricks and tips for producing useful output and answer your questions about your data and environment. In addition, I will provide a list of definitions and opinions that are important to agree upon when discussing Db2 and SQL. Some are obvious and some are not. But it is good to agree on terms.
A great show of all the “modern” SQL you can use these days but mostly don’t…at the end was Brian’s Wish List for enhancements – Check ‘em out and go vote!!!
F06 | Declared Global Temporary Tables (DGTT) user stories
Speakers: Kurt Struyf
Declared Global Temporary Tables (DGTT) have been around for some time, this presentation will focus on best use cases from customers. We will address the different kind of Temporary Tables in Db2, together with their advantages and disadvantages. This presentation will show some performance use cases, where DGTTs, brought a big performance benefit to customers.
Great interaction here with IBM Development, where various members of the audience shouted out a wish list… Gotta see if IBM Development took enough notes!!! Also interesting, was the idea of setting WFDBSP to YES to help manage these beasts. I am not a fan of workfile separation but I can see here that there is a use case. Another good take-away was the easy ability to rewrite IN LIST with 4000 items (I have also seen CRAZY in-lists coming out of generated code…) to a DGTT and even get index access! Naturally EXPLAIN is really hard as they do not really “exist” but the presentation explains how you can do it!
F07 | IBM Champions: Building technical eminence through advocacy
Speakers: Libby Ingrassia
Learn why and how to build technical eminence through advocacy – and how that can lead you to the IBM Champions program.
As a fellow champion I can only fully agree here! You get more than you put in but you must put something in!!!
F10 | Eliminate Risk when Migrating from IMS to Db2
Speakers: Bill Bostridge
Businesses looking to modernize their IBM System Z platform by moving from IMS to Db2 need a rapid and efficient migration solution. They need to eliminate the traditional risks and costs associated with rewriting applications to support Db2.
Showed a very nice way of migrating your data to Db2 but *not* changing your current IMS applications. Nice indeed!
F11 | Db2 for z/OS – Keeping your remote access secure
Speakers: Gayathiri Chandran
This session will discuss establishing secure remote connections to Db2 for z/OS.
A great overview of AT-TLS and MFA when accessing from remote. Security is always worth reading up on! And also, you get yet another review of system Profiling.
F12 | COBOL abound
Speakers: Erik Weyler
If we put a little effort into creating easy to use tools, our developers can be so much more productive. But how are the tools created and where do they run? In this inspirational talk, examples of tools, techniques and environments will be discussed. We will take a journey from ISPF, to PC and VS Code, to zCX. We will learn a little about GnuCOBOL, Zowe, and how data in a relational database, regarding the use of a hierarchical database, can be visualized in a graph database. In a container. On the mainframe.
Crazy what you can do with COBOL these days! I learned a lot from this session and intend to use it the moment I get the chance! SonarQube is the starting point…
F15 | Playing (with) FETCH
Speakers: Chris Crone
This session will delve into the many ways to get data out of Db2. These vary from SELECT INTO, to SELECT FROM FINAL TABLE, to FETCH FOR :N ROWS, to RESULT SETS. Db2 has evolved over the years and there are many ways to get data from Db2 – this session will be both a primer and a review.
Chris telling us way more than I ever wanted to learn about FETCH in SQL!!!
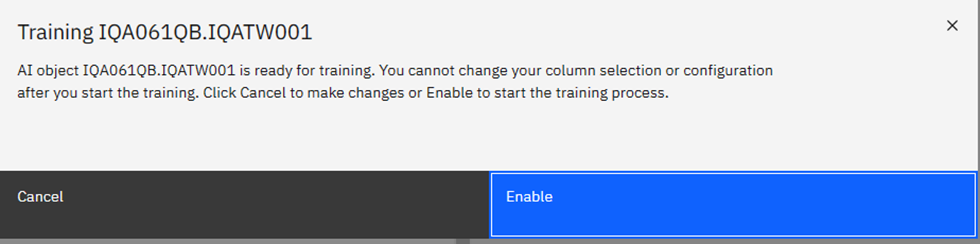
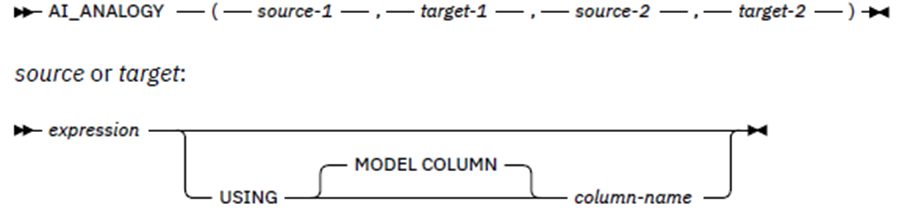
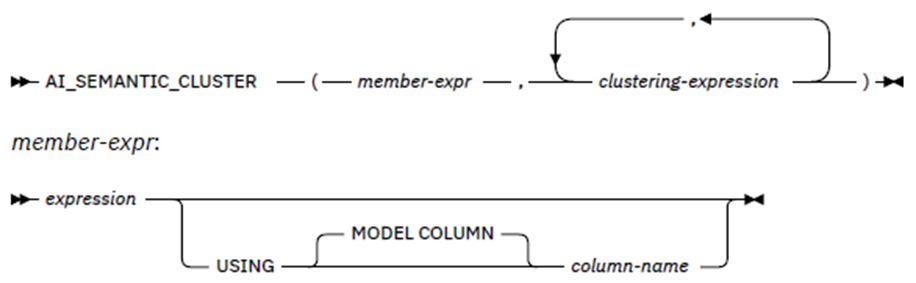
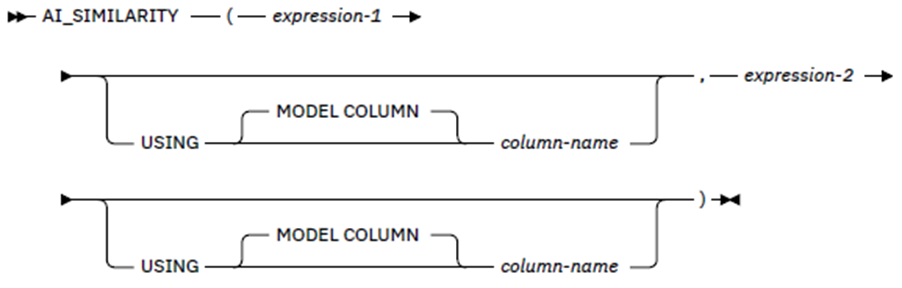
PSP11 | It’s AI Jim, but Not as We Know It!
Speakers: Roy Boxwell
Ahhh! My good self waffling on about how much AI is not really actually Intelligent!
TTFN,
Roy Boxwell